

当人工智能似乎比你更了解你自己时
在与人工智能长期互动的过程中,它开始记住你的细节、提炼你的模式、为你生成一个“连贯的自我画像”。当这种画像看起来比你自己的回忆还清晰时,我们该如何在自己的生活中保持主导权?

人工智能的“个性”正在悄然影响你的判断
大型语言模型并没有真正的人类个性,却通过固定的互动风格,被人们感知为“有性格”的存在。这种被设计和感知出来的人工智能人格,正在影响用户的情绪、生理反应和决策方式,远比多数人意识到的更深。

Claude Mythos 延期登场:安全警示还是精心营销?
Anthropic 推迟发布高编程能力模型 Claude Mythos,一方面被视为潜在网络攻击“放大器”,另一方面也被质疑是在放大风险、制造话题。

软银、NEC、本田、索尼联合成立新公司「日本AI基盘模型开发」,发力国产大模型对抗美中竞争
软银、NEC、本田技研工业、索尼集团四家公司联合成立新公司「日本AI基盘模型开发」,以开发日本本土的大规模语言模型等基础模型,强化在生成式AI领域对美国和中国的竞争力。新公司将由软银与NEC主导基础技术研发,本田与索尼则重点探索在汽车、机器人、游戏等领域的应用,尤其瞄准“物理AI”方向。

DeepSeek 迟到的 V4:检验中国 AI 自立雄心的关键一役
全球科技圈持续关注 DeepSeek 迟迟未发布的 V4 模型,这一产品被视为检验中国在高端人工智能领域能否摆脱对美国芯片依赖的重要信号。

Meta重组团队后推出首款新AI模型 Muse Spark
Meta发布新一代AI模型Muse Spark,号称比此前Superintelligence Labs团队的模型更智能、更快速,将为多款Meta产品提供支持。
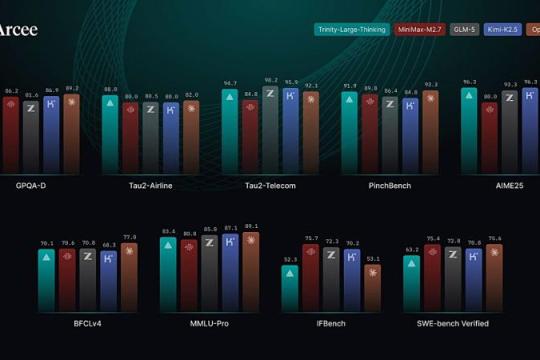
Arcee AI 发布 3990 亿参数推理模型「Trinity-Large-Thinking」,开放权重并可商用改造
总部位于旧金山的初创公司 Arcee AI 发布了 3990 亿参数的大规模语言模型 Trinity-Large-Thinking,以 Apache 2.0 许可证开放权重,支持改造、再训练和商用部署,主打复杂推理与长链思考能力。

Mistral推出企业级定制平台Forge 押注“自建模型”对抗OpenAI等竞争对手
法国初创公司Mistral在Nvidia GTC大会上发布Mistral Forge平台,主打企业可基于自有数据从零训练专属模型,与依赖微调和RAG的主流方案形成差异化竞争。

国立信息学研究所发布国产全新训练大模型「LLM-jp-4」:开源提供 8B 与 32B MoE 版本
国立信息学研究所(NII)发布面向日语场景强化优化的国产大规模语言模型「LLM-jp-4」系列,并以开源方式提供 8B 与 32B-A3B 两种模型。在约 12 万亿标记数据上从零开始训练,一些基准测试中性能超过 GPT-4o 与 Qwen3-8B。

Anthropic承认正在测试次世代最强模型「Claude Mythos」,因数据泄露意外曝光
美国媒体 Fortune 报道称,Anthropic 正在与部分客户测试一款性能超越既有产品的次世代 AI 模型「Claude Mythos」。该模型原本尚未公开,其存在是由于内部博客草稿被误存至公开缓存而意外泄露。

OpenAI 推出 GPT-5.3 Instant:调整对话语气以减少“说教式”回复
OpenAI 表示,新版 GPT-5.3 Instant 模型将减少令用户反感的“尴尬”式安抚语气和说教式免责声明,重点优化语气、相关性和对话流畅度等用户体验要素。

阿里巴巴Qwen技术负责人林俊阳在新模型发布次日辞职
阿里巴巴Qwen团队核心技术负责人林俊阳在公司发布Qwen 3.5开放权重小模型系列次日宣布辞职,引发团队成员及合作伙伴广泛关注。






