

国立信息学研究所(NII)于 2026 年 4 月 3 日正式发布新一代国产大规模语言模型(LLM)「LLM-jp-4」系列,并以开源许可证的形式公开「LLM-jp-4 8B 模型」和「LLM-jp-4 32B-A3B 模型」。
这两款模型在约 12 万亿标记(token)的语料上从零开始训练,重点强化日语能力。根据 NII 公布的部分评测结果,在若干基准测试中,LLM-jp-4 的表现已经超过 GPT-4o 和 Qwen3-8B 等海外主流模型。
基于「LLM-jp」项目,从零开始训练的国产 LLM
此次发布的模型出自 NII 牵头推进的 LLM 项目「LLM-jp」,该项目以提升日语处理能力为核心目标,面向研究机构、企业和开发者开放使用。
与在现有模型上进行微调的方式不同,LLM-jp-4 系列采用的是完全从零开始的「全新训练(full scratch)」路线:
- 预训练阶段使用了包含日语、英语以及程序代码在内的大规模语料,总计约 10.5 万亿标记;
- 加上指令微调等后续数据,总训练规模约达 12 万亿标记。
训练数据覆盖:
- 大规模日语 Web 文本;
- 英语文本数据;
- 各类编程代码等。
两大开源模型:8B 与 32B-A3B
本次公开的主要模型包括以下两种:
■ LLM-jp-4 8B 模型

- 约 86 亿参数
- 基于 Llama 系架构
■ LLM-jp-4 32B-A3B 模型
- 约 320 亿参数
- 采用 MoE(Mixture of Experts,专家混合)结构
- 在 128 个专家中,推理时动态启用约 3.8B 参数的子集
通过引入 MoE 结构,模型在保持大模型表达能力的同时,能够显著提升计算效率,降低推理成本,更适合在实际应用中部署。
日语基准测试表现突出
在 NII 公布的评测结果中,LLM-jp-4 系列在日语综合评测基准「llm-jp-eval v2.1.3」上的多个任务中取得了较高分数。
基于 llm-jp-eval v2.1.3 的日语基准评测结果
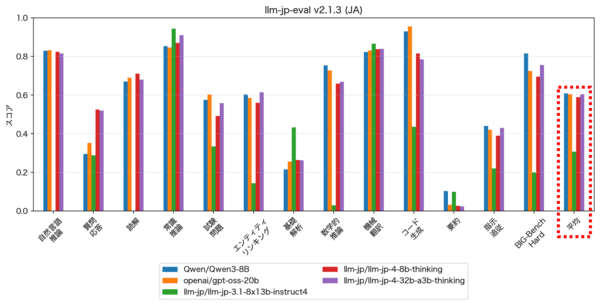
其中,32B-A3B 模型在对话能力评估指标(如 MT-Bench)上表现尤为亮眼,据称在部分指标上已超过 GPT-4o 和 Qwen3-8B。
规划更大规模模型,2026 年内陆续发布
根据 NII 的介绍,团队正在推进更大规模模型的研发,计划在 2026 年内陆续公开:
- LLM-jp-4 32B
- LLM-jp-4 332B-A31B
随着企业与高校在日语大模型领域的研发日益活跃,LLM-jp-4 的开源发布将为日本语大模型的研究与应用提供更坚实的基础设施,推动本土化语言技术生态的进一步发展。









