

尽管人工智能系统本身并不会主动产生偏见,但它们会从训练数据中继承已有的偏见,并在学习过程中不断放大和重复这些偏见,最终导致决策结果系统性地不公平。更棘手的是,偏见究竟在系统的哪个环节被引入并不容易识别,因为大多数人工智能系统只给出最终结论,而不会展示中间推理过程,使得不公平模式往往难以及时被发现。
为应对这一问题,大阪都立大学信息学研究科野岛佑介教授带领的计算智能研究团队,开发了一系列“模糊”人工智能系统,尝试在模型设计之初就平衡预测准确性与决策公平性。这项研究成果已发表在期刊《IEEE Transactions on Fuzzy Systems》上。
所谓模糊系统,是一种利用接近人类思维方式的规则来进行推理和决策的人工智能方法。与传统那种非黑即白的“是/否”规则不同,模糊系统允许程度上的差异,例如“同意程度较高”“同意程度非常高”等,从而更适合处理现实世界中大量存在的灰色地带和模棱两可的情况。
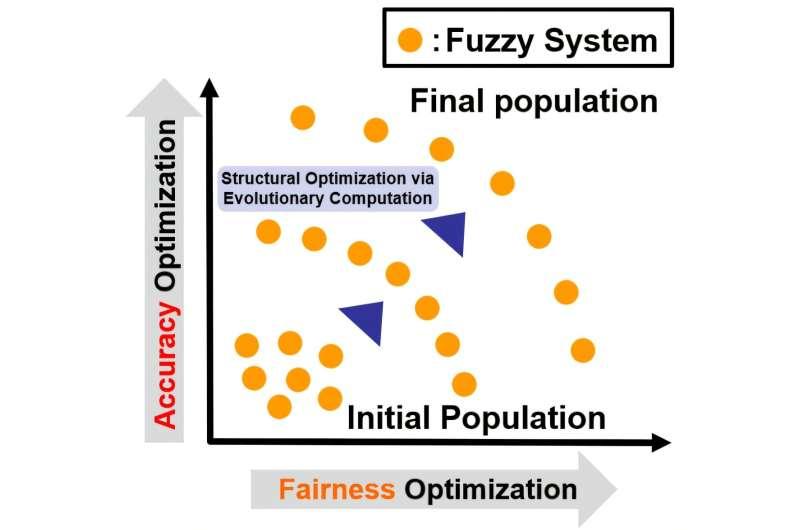
研究团队采用了一种名为“多目标基于模糊遗传的机器学习”的方法。在这一框架下,学习系统会进化出大量候选模型,这些模型在设计时就以实现公平决策为目标之一。与以往大多先追求预测准确性、训练完成后才额外评估公平性的做法不同,该研究将公平性直接纳入训练目标,使模型在学习过程中同时优化准确性与公平性。
在模型进化过程中,每一个候选模型都会从两个维度进行评价:预测准确性和决策公平性。算法通过多目标优化搜索,使这两者之间达到尽可能理想的平衡,而不是单纯追求某一方的极致表现。
为了验证方法的有效性,研究人员选用了四个常用的公平性基准数据集,这些数据集在性别、种族等敏感属性上容易产生偏见决策,分别涉及以下四类现实任务:
- 预测个人年收入是否超过 5 万美元;
- 评估个人信用风险是否良好;
- 判断在接触某项营销活动后是否会进行银行存款;
- 预测被告在两年内是否会再次犯罪。
这些数据集均来源于真实世界场景,因此更能反映实际应用中可能出现的偏见问题。
“我们设计的模型在准确性和公平性两个方面都优于其他模型。”论文第一作者、研究生小西健表示。
通过分析影响决策的关键因素,以及人工智能在准确性与公平性之间如何进行权衡,研究人员能够更好地理解在优化过程中这两者平衡关系是如何形成的。这种对内部机制的可视化和解释,有助于未来进一步改进模型结构,构建更加准确且更加公平的人工智能系统。
“本研究的成果将推动人工智能的发展方向,从单纯追求准确性,转向同时重视透明性和公平性。”野岛教授指出,“我们希望此类研究能够帮助构建一个值得信赖的人工智能社会,使人们可以放心地依赖人工智能来做出复杂而细致的决策。”









