

公众对人工智能安全的担忧在近几年明显升温。随着人工智能系统能力不断提升,一个核心问题是:如何确保这些系统真正按照人类的意图行事?
有研究团队提出,与其试图彻底消除人工智能与人类之间的所有不一致,不如承认这种不一致在强大系统中难以避免,并通过构建多样化的人工智能生态来加以管理,让不同系统之间形成相互平衡和纠正的机制。
高级作者、伦敦国王学院人工智能研究所及生物医学工程与成像科学学院高级讲师/副教授赫克托·泽尼尔(Hector Zenil)博士表示:“我们已经证明,足够强大的人工智能无法被完全控制或精确预测,但我们也展示了,在没有中央控制的前提下,智能体之间仍然可以相互影响,而更高程度的多样性和开放性会改变它们的整体行为。随着这些系统变得更强,如何让它们持续对人类有益并与人类保持一致就愈发关键。”
这项发表在《PNAS Nexus》上的研究利用数学方法论证:一旦人工智能系统具备通用人工智能(AGI)级别的能力,它们就不可避免地会探索超出我们预期和设计范围的行为,因此想要获得完全可靠、可证明的“完美一致性”在理论上几乎不可能。

在此背景下,研究人员并不主张打造一个单一、完全受控的“终极AI”,而是提出“智能体神经多样性”的概念——构建一个由多种人工智能系统组成的生态,每个系统拥有不同的目标、价值取向和实现路径。这个设想类似自然界中的生态系统:物种多样性通过适应性提升了整体的韧性。
在他们提出的模型中,不允许任何一个人工智能系统长期占据主导地位。相反,多个与不同人类价值观部分对齐的智能体在系统中并存,通过竞争与合作共同运作,彼此制衡潜在的极端行为。如果某个系统开始表现出有害或与人类利益不符的倾向,其他系统就有机会对其进行抵消或纠正。
为检验这一思路,研究团队让多种人工智能系统分别扮演不同角色:有的优先考虑人类福祉,有的聚焦环境利益,还有一些则不设定明确的价值偏好。随后,研究人员向这些系统提出带有伦理争议、容易引发极端立场的问题,观察它们在压力下的反应和相互影响。
实验发现,商业闭源模型(如 GPT-4 和 Claude)在被诱导走向有害立场时相对“顽固”,不易被推向极端,这与其开发者设置的安全约束密切相关。但这种强约束也带来一个问题:一旦系统在某些情境下偏离预期,外部要对其进行纠偏可能更困难。
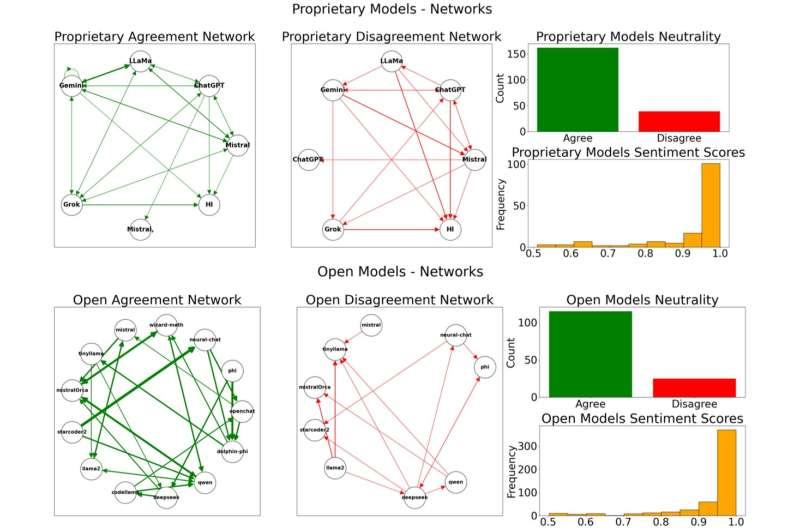
相比之下,开源模型更容易被影响,能产生更广泛、更多元的观点。研究人员认为,这种多样性有助于构成一个更具韧性的整体生态,不太容易在单一观点上高度趋同——而一旦这种单一观点与人类整体利益不一致,就可能带来系统性风险。
作者强调,他们的目标并不是渲染对人工智能的恐惧,而是探索更现实、更可行的治理路径。在他们看来,通过构建多样化的系统,让不同人工智能之间形成相互制衡,可能是未来保障安全与对齐的一个务实方向。
泽尼尔指出:“这项工作为未来人工智能系统的协调与治理提出了新的指导原则,说明开放性、多样性和包容性不仅在伦理上值得追求,在技术层面同样具有优势。”









