

瓦伦西亚理工大学人工智能研究所(VRAIN)与 ValgrAI 的研究团队参与开发了一种名为 ADeLe 的新方法。该方法能够在大型语言模型(LLMs)尚未真正执行某项新任务之前,就较为精确地判断其在该任务上是会成功还是失败。同时,ADeLe 还能清晰界定任一模型在推理方面的能力上限。
这项成果已发表在《自然》杂志上,被视为重要进展。以往的评估方法通常只能告诉我们模型在某个既定测试集上的得分,而 ADeLe 则通过更具“认知”视角的分析,在模型实际部署前就对其行为进行解释和预测。这样一来,企业在将新模型投入生产环境之前,就能预先识别潜在错误,避免在真实应用中才暴露出严重问题。
研究团队指出,通过这种认知化评估,他们首次能够在模型上线前,以约 90% 的准确率预测其是否能解决一项新任务。瓦伦西亚理工大学 VRAIN 研究员 Fernando Martínez-Plumed 表示,这对工业界尤为关键,因为可以提前发现系统缺陷,减少因发布表现不佳模型而带来的高昂成本。
该研究由瓦伦西亚理工大学计算机科学教授、VRAIN 研究员、ValgrAI UMI 成员 José Hernández-Orallo 领衔,参与者包括瓦伦西亚理工大学计算机科学高级讲师兼 VRAIN 研究员 Martínez-Plumed,VRAIN 博士生 Yael Moros-Daval 和 Kexin Jiang-Chen,以及同时隶属于 ValgrAI 和 VRAIN 的博士生 Behzad Mehrbakhsh。
严格评估 AI 能力的关键进展
在当前 AI 技术快速演进、应用场景不断扩大的背景下,这一方法对研究机构、企业、第三方评估者以及政策和监管部门都具有重要意义。各方一直呼吁建立更加严格、可扩展且标准化的 AI 能力评估体系,尤其是在安全审计等关键环节。
论文中指出,迄今为止,AI 评估方法尚不足以应对快速扩张且日益多样化的 AI 生态系统。如何理解并预测通用 AI 系统在不同任务上的表现,已经成为迫切需求。ADeLe 提供了一种系统化且可扩展的方案,弥补了传统评估在可解释性和预测能力方面的不足。
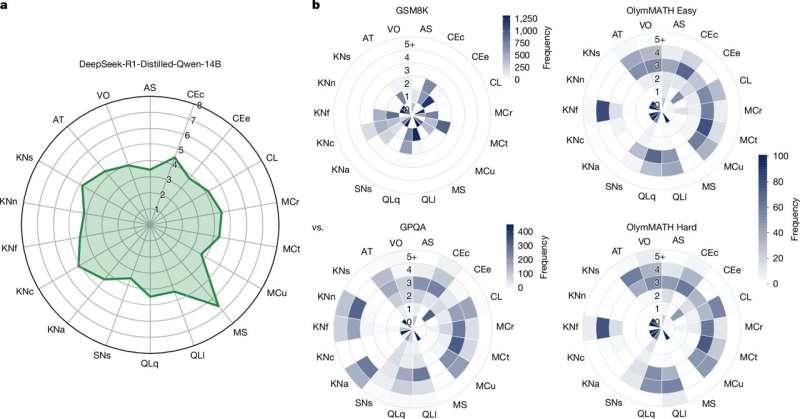
18 个认知能力维度
这项工作的核心在于,不再只看整体准确率等单一指标,而是从更细致的能力维度入手,从而实现对未知任务表现的可迁移预测。
研究团队将大型语言模型在各种认知任务中需要动用的能力,归纳为 18 个关键维度,例如注意力、推理能力以及任务本身的独特性等。随后,他们根据现实任务对这些能力的依赖程度,对任务在各个维度上进行打分。
在此基础上,通过让模型完成数量足够多、难度层次不同的“打分任务”,研究人员为每个模型构建出一份能力画像。借助这份画像,就可以推断模型在尚未直接测试过的新任务上的成功概率。
主要结论
利用 ADeLe,研究团队对大量现有 AI 性能基准进行了系统分析,并得出四个主要结论:
- 当前许多 AI 基准并未真正测量它们声称要测量的能力,往往在无意中考察了其他方面的能力。
- 不同 AI 模型在各项能力维度上的强弱分布并不相同,这与模型规模、推理策略以及模型家族等因素密切相关。
- ADeLe 能够较为准确地解释并预测 AI 系统在特定新任务上是会成功还是失败,而不仅仅是事后打分。
- 关于“AI 是否具备推理能力”的争论在一定程度上是有道理的,但实际上涉及不同层次的难度:有些测试只需要基础问题求解能力,而另一些则要求更高阶的逻辑推理、抽象能力和深度领域知识。
研究作者在总结中指出,ADeLe 呈现出的最清晰图景之一是:推理型模型(例如 OpenAI 的 o1)在逻辑和数学任务上展现出真实且可量化的性能提升,同时在一些看似意料之外的方面——例如更好地理解用户的真实意图——也有显著进步。









