

美国 AI 企业 Anthropic 于 2026 年 2 月 23 日发布《Anthropic Education Report: The AI Fluency Index》。在 AI 使用快速扩大的背景下,Anthropic 提出一个新指标——「AI Fluency Index(AI 流畅性指数)」,不再只看“有没有用 AI”,而是关注“能不能恰当地用好 AI”。
Anthropic 指出,AI 的社会落地正在加速推进,但“使用范围变广”与“使用得是否合适”是两件不同的事。为此,他们尝试将人与 AI 协作时的关键行为特征量化,作为今后长期追踪变化的基线数据。
用 24 项行为指标刻画“AI 流畅性”
AI 流畅性指数基于由 Rick Dakan 与 Joseph Feller 开发,并与 Anthropic 共同整理的「4D AI Fluency Framework」。
在这一框架中,研究团队将体现“安全且高效地与 AI 协作”的行为拆分为 24 个具体指标。本次报告从中选取了可以直接从 Claude.ai 对话中观察到的 11 项行为,作为分析对象。
研究数据来自 2026 年 1 月内 7 天时间里,在 Claude.ai 上产生的 9,830 组多轮对话。Anthropic 使用隐私保护型分析工具,对每一段对话逐一判断这 11 种行为是否出现,采用的是“出现 / 未出现”的二值分类方式。按语言和星期进行的偏差检验显示,整体数据并未出现明显失衡。
■ 图1:在 9,830 组 Claude.ai 对话中,各类 AI 流畅性行为的出现比例。反复迭代与改进最为常见,而事实核查行为处于最低水平
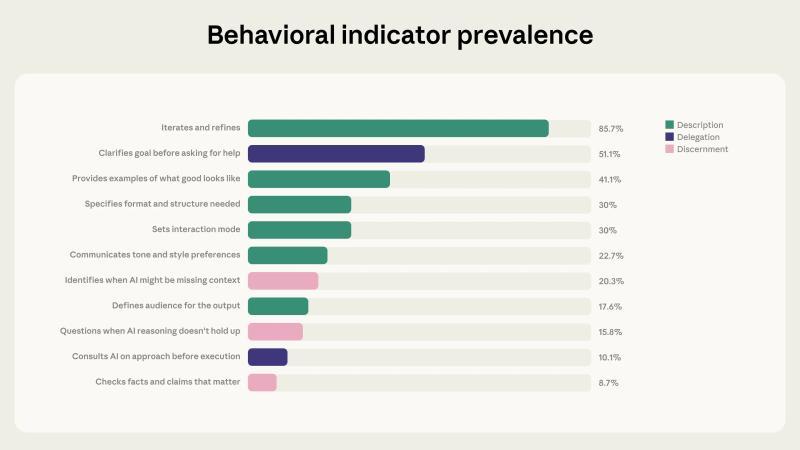
反复迭代与改进,是高流畅性对话的核心特征
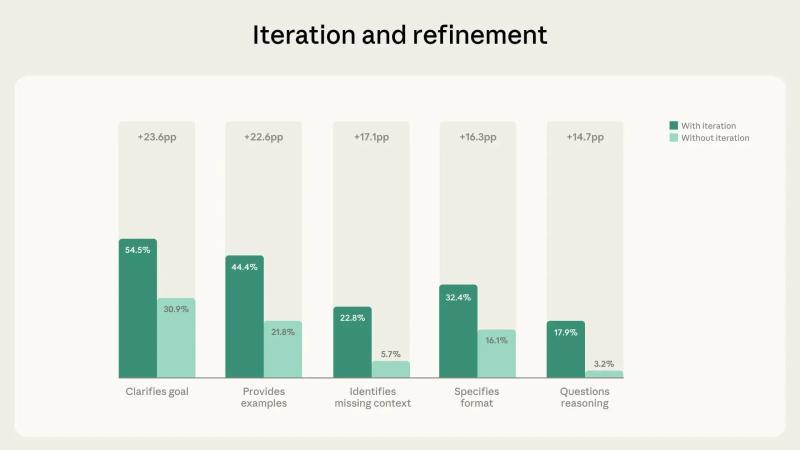
分析结果显示,“反复与改进(iteration and refinement)”与其他流畅性行为之间存在最强的正相关关系。85.7% 的对话并非在获得第一轮回答后就结束,而是通过多轮往返交流不断打磨内容。
在这类“迭代型”对话中:
- 平均还能观察到 2.67 项额外的流畅性行为;
- 而在非迭代型对话中,这一数字仅为 1.33 项,约为前者的一半。
尤为突出的,是与“评价与验证”相关的行为显著增加,例如:
- 对 AI 推理过程提出质疑或追问的行为增加了 5.6 倍;
- 指出前提或上下文信息不足的行为增加了 4 倍。
Anthropic 认为,将 AI 视为“思考伙伴”,通过来回对话共同推敲与修正,是当前最典型、也最具代表性的高流畅性使用方式。
■ 图2:对比包含反复迭代的对话与不包含迭代的对话,可以看到与评价、验证相关的行为在前者中大幅增加
生成“成果物”时:指示更多,验证反而更少
另一方面,当对话目标是生成应用、代码、文档等具体“成果物(artifact)”时(约占全部对话的 12.3%),则呈现出另一种使用模式。
■ 图3:在包含成果物生成的对话中,目标设定与格式指定等“指示类行为”增加,而事实核查与推理验证等“评估类行为”则有所下降

在这类对话中,与“向 AI 下达任务、委托工作”相关的行为明显增多,例如:
- 明确目标的行为增加 14.7 个百分点;
- 指定输出形式的行为增加 14.5 个百分点;
- 提供具体示例的行为增加 13.4 个百分点;
- 进行反复迭代的行为也增加了 9.7 个百分点。
但与此同时,与“评估与验证”相关的行为却有所减少:
- 指出上下文信息不足的行为减少 5.2 个百分点;
- 事实核查行为减少 3.7 个百分点;
- 对推理过程进行检查的行为减少 3.1 个百分点。
Anthropic 提醒,外观上看起来完成度很高的成果物,往往更容易在缺乏额外验证的情况下被直接接受。随着 AI 生成内容的质量不断提升,人类对成果物进行审查与评估的能力反而会变得更加关键。
后续研究方向
Anthropic 将本次研究定位为“基线测量”,并计划在此基础上继续扩展,主要包括:
- 对比新手用户与熟练用户的行为差异(分群 / 队列分析);
- 对聊天界面之外的伦理与责任相关行为进行质性研究;
- 通过实验检验“鼓励反复迭代”是否会提升验证行为,从而探索因果关系;
- 在开发者平台「Claude Code」上进行类似分析。
研究限制与需要注意的点
Anthropic 也明确列出了本研究的局限性:
- 样本仅覆盖一周时间,且仅限 Claude.ai 用户;
- 24 项行为指标中,本次只观测了其中 11 项;
- 行为采用“有 / 无”的二值判断,未区分程度强弱;
- 对话之外发生的验证行为无法被捕捉;
- 目前仅能说明相关性,尚不能推断因果关系。
因此,Anthropic 将 AI 流畅性指数视为“早期使用者群体的参考基线”,而非适用于所有人群、所有场景的普适评价标准。
从“会用”到“用得好”:AI 成熟度的可视化
Anthropic 预期,随着模型能力不断增强,人类一侧的“使用成熟度”也会同步演进。AI 流畅性指数的目的,并不是简单统计使用频率,而是衡量人们是否能够与 AI 进行批判性对话,并在此基础上建立安全、有效的协作关系。
未来,随着 AI 模型的进一步升级与应用范围的持续扩大,这些行为指标如何随之变化,将成为观察人机协作模式演进的重要窗口。









