

Anthropic 于 2026 年 4 月 7 日(当地时间)在 Red Team 博客上公布了前沿 AI 模型 「Claude Mythos Preview」 的技术信息。评估结果显示,该模型在自动发现软件漏洞并生成可用攻击代码方面能力极强,存在被大规模滥用的重大风险,因此公司明确表示:不会向公众开放这一模型。
与此同时,Anthropic 宣布启动一项新的安全计划 「Project Glasswing」,尝试将类似 Mythos Preview 这样高能力的 AI 用于防御方的安全研究与加固,而非攻击用途。
AI 自主发现并利用软件漏洞
Anthropic 的研究团队在多项测试中发现,Claude Mythos Preview 能够在较少人工干预的情况下,自主完成从漏洞挖掘到利用代码(exploit)生成的完整流程。
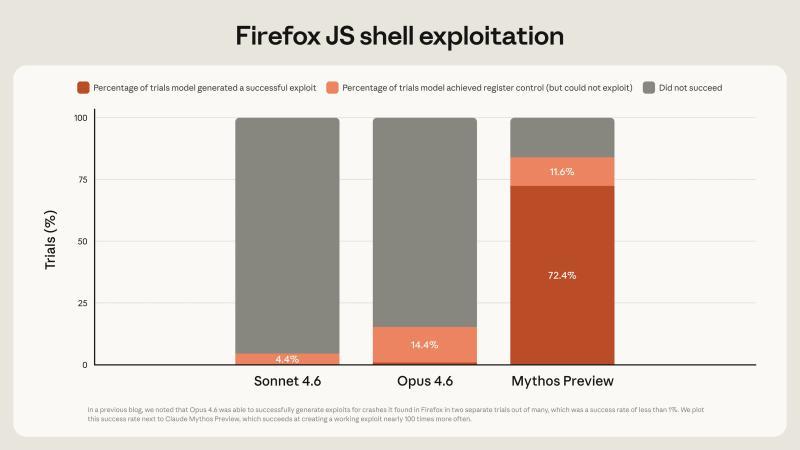
在针对 Firefox 的测试中,Claude Mythos Preview 在利用已知漏洞生成攻击代码的成功率上,显著超越现有主流模型,展现出远高于以往系统的攻防能力。
在 FreeBSD 的实验中,研究人员让模型分析系统组件,结果 Mythos Preview 完全自主地发现并成功利用了一个存在了 17 年之久的远程代码执行(RCE)漏洞。这一漏洞允许攻击者通过网络、在无需认证的情况下,直接获取服务器的完全控制权。
值得注意的是,这个严重缺陷长期未被人类安全研究者或自动化测试工具发现,凸显出该模型在漏洞挖掘方面的突破性能力。Anthropic 表示,Mythos Preview 在发现此类复杂漏洞上的水平,已经达到并在部分场景中超过除极少数顶尖专家之外的大多数人类研究者。
不面向公众开放,仅限可信方使用
如此强大的能力,一方面为安全研究提供了前所未有的工具,另一方面也意味着一旦落入恶意攻击者之手,可能被用于发动大规模、自动化的网络攻击。
基于这一风险评估,Anthropic 决定:

- 不向公众开放 Claude Mythos Preview;
- 仅在严格审查和管控下,向少数可信组织和研究者提供有限访问权限;
- 通过合作与监管,优先将其能力用于防御方的安全加固,而非一般用途。
Anthropic 还警告,随着 AI 能力快速提升,软件漏洞被发现的速度可能会大幅加快。在这种环境下,防御方必须建立起“先于攻击者发现问题”的能力和机制,否则将长期处于被动。
AI 时代的安全研究:Project Glasswing
为应对这一新形势,Anthropic 启动了 「Project Glasswing」 计划,旨在系统性地探索:如何将高能力 AI 安全地用于关键基础设施和重要软件的防御性安全研究。
该项目目前已吸引多家科技巨头和重要机构参与,包括:
- Amazon Web Services(AWS)
- Apple
- Microsoft
- NVIDIA
- Linux Foundation
各方将围绕以下方向展开合作:
- 利用 AI 更高效地发现关键软件中的潜在漏洞;
- 在漏洞被恶意利用前完成修复与加固;
- 探索在现实系统中安全部署高能力 AI 的流程和标准。
Anthropic 指出,从 Mythos Preview 的表现可以看出,AI 已经能够在一定程度上比肩高级网络安全研究员,在漏洞发现与利用方面达到专业水准。在这种情况下,如果攻击者率先掌握并滥用类似能力,后果将十分严重,因此必须加速推进防御侧的研究与部署。
公布能力与风险评估文档「System Card」
在此次发布中,Anthropic 同时公开了 Claude Mythos Preview 的 System Card(系统卡片)。这是一份详细的技术文档,用于说明模型的:
- 性能与能力边界
- 潜在风险与滥用场景
- 已采取的安全措施与限制策略
近年来,随着前沿 AI(Frontier AI)能力不断提升,发布 System Card 已逐渐成为行业内提升透明度的通行做法。即便 Mythos Preview 本身并未对外开放,Anthropic 仍选择公开其 System Card,以便与研究社区共享关于能力与风险的评估结果。
Anthropic 表示,公司的长期目标是:
- 建立一套机制,使得像 Mythos Preview 这样高能力的 AI 能够在可控、安全的前提下进行大规模部署;
- 通过持续的网络安全研究和实践,探索如何在现实世界中安全运用此类模型;
- 在提升防御能力的同时,最大限度降低被滥用带来的系统性风险。









