

中国 AI 企业 DeepSeek 于 2026 年 4 月 24 日(日本时间)正式发布开放大模型「DeepSeek‑V4」预览版。该系列包含两条产品线:面向高性能场景的「DeepSeek‑V4‑Pro」以及主打轻量与高速度的「DeepSeek‑V4‑Flash」,两者均原生支持 100 万 Token 的超长上下文。模型以开放权重(Open Weights)形式发布,同时也可通过 API 与 Web 应用直接调用。
■ DeepSeek‑V4‑Pro 与 DeepSeek‑V4‑Flash 的主要规格:Pro 采用 1.6 万亿参数的 MoE 架构,Flash 则定位为轻量高速版本

Pro 版 1.6 万亿参数,Flash 版 2840 亿参数的 MoE 架构
DeepSeek‑V4‑Pro 采用 Mixture of Experts(MoE)架构,总参数量达到 1.6 万亿,推理时激活参数为 490 亿。DeepSeek‑V4‑Flash 同样为 MoE 结构,总参数量为 2840 亿,激活参数为 130 亿,面向对延迟与成本更敏感的应用场景。
两款模型均将 100 万 Token 上下文作为标准能力提供:Pro 版以「Expert Mode」形态上线,Flash 版则以「Instant Mode」提供服务。API 已同步开放,支持与 OpenAI、Anthropic 兼容的接口形式,便于现有系统平滑接入。
100 万上下文标准化,长文推理效率显著优化
在本次发布中,DeepSeek 将 1M Token 长上下文明确定位为「标准规格」。在技术实现上,DeepSeek‑V4 引入了自研的注意力机制「DeepSeek Sparse Attention」,通过结合 Token 级压缩与注意力稀疏化,在保持长文理解能力的前提下,降低计算与内存开销。
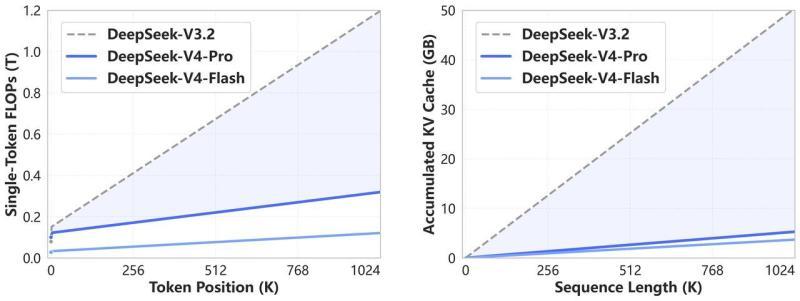
官方介绍称,相比以往模型,该机制在处理超长文档时显著减少了计算量(FLOPs)和 KV Cache 占用,从而提升了在长文档分析、多轮复杂对话以及 Agent 长链路任务中的实用性。
■ 在长上下文场景下,DeepSeek‑V4 相比既有模型显著降低了计算量(FLOPs)与 KV Cache 使用量
基准测试中宣称达到开放模型第一梯队
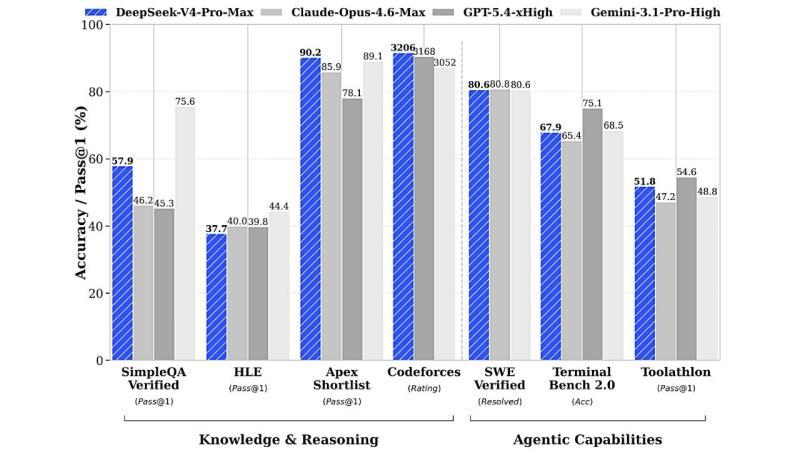
DeepSeek 公布的评测结果显示,在「DeepSeek‑V4‑Pro‑Max」配置下,该模型在多项基准测试中超越现有主流开放模型。
在知识与推理能力方面,DeepSeek‑V4‑Pro‑Max 在 SimpleQA Verified、Apex Shortlist、Codeforces 等测试中取得高分。尤其是在 Codeforces 评测中,其给出的评级为 3206,官方称这一水平已达到或超过 GPT‑5.4(3168)与 Gemini‑3.1‑Pro(3052)等闭源模型。
在衡量 Agent 能力的 SWE Verified、Toolathlon 等基准中,DeepSeek‑V4 也展现出较强的竞争力,强调其在代码生成、工具调用与任务执行等方面的综合表现。
■ DeepSeek‑V4‑Pro‑Max 与主要模型的基准对比:在知识/推理与 Agent 能力两大维度均取得高分
细分基准中在多类任务上保持高水准
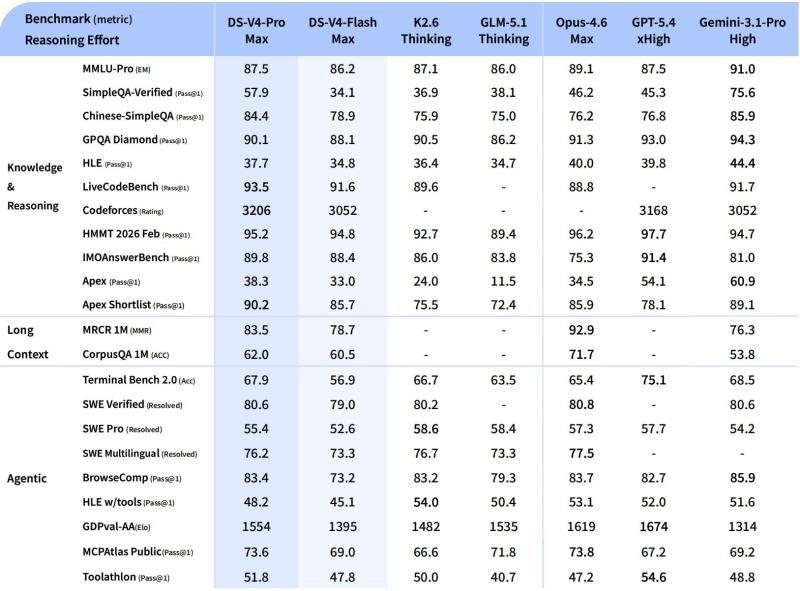
DeepSeek 还公布了更为细致的评测表格,涵盖 MMLU‑Pro、GPQA、HLE、LiveCodeBench 以及多种 SWE 系列基准等。整体来看,DeepSeek‑V4 在知识问答、推理、长文理解、代码生成与工程类任务等多个维度上,均处于开放模型的高位水准。
尤其在代码与推理相关任务上,DeepSeek‑V4 被定位为当前开放权重模型中的「强竞争者」,旨在缩小与顶级闭源模型之间的差距。
■ DeepSeek‑V4 的详细基准列表:在知识、长文处理与 Agent 任务等多个领域获得全面评估
面向 Agent 场景设计,强化代码与执行能力
DeepSeek 表示,DeepSeek‑V4 在设计之初就将与各类 AI Agent 的集成作为重要目标。官方称,该模型可与 Claude Code、OpenClaw、OpenCode 等 Agent 系统进行集成,并已在公司内部的 Agent 式编程与开发流程中投入使用。
在后训练阶段,DeepSeek 采用了针对数学、编程与 Agent 任务等多个子领域分别优化、再进行整合的策略,以在推理能力与实际执行能力之间取得平衡。这种多专长模型融合的方式,旨在提升模型在复杂任务拆解、工具调用与多步骤执行上的表现。
API 已开放,旧模型将于 7 月停用
DeepSeek‑V4 的 API 已随发布同步上线,现有用户只需切换调用的模型名称即可迁移使用。API 同时支持 Thinking 模式与 Non‑Thinking 模式,以适配不同的延迟与成本需求。
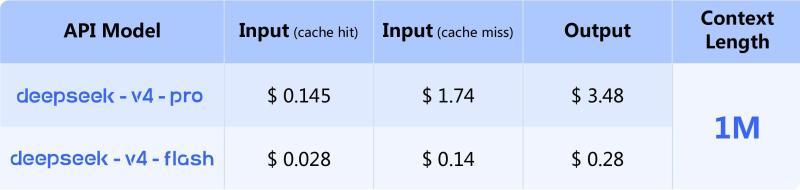
官方公布的定价为:
- DeepSeek‑V4‑Pro
- 输入:缓存命中时 0.145 美元 / 1M Token,未命中时 1.74 美元 / 1M Token
- 输出:3.48 美元 / 1M Token
- DeepSeek‑V4‑Flash
- 输入:0.028 美元 / 1M Token(命中)/0.14 美元 / 1M Token(未命中)
- 输出:0.28 美元 / 1M Token
其中 Flash 版明显面向高性价比与高吞吐场景,适合大规模部署与对成本敏感的业务。
■ DeepSeek‑V4 的 API 价格:Flash 版主打低成本与高速度
DeepSeek 同时宣布,现有的「deepseek‑chat」与「deepseek‑reasoner」模型将于 2026 年 7 月 24 日(UTC)正式停止服务,用户需在此之前完成向 DeepSeek‑V4 系列的迁移。
总体来看,DeepSeek‑V4 以开放权重形式提供,将长文处理、推理能力与 Agent 能力进行一体化设计,试图在开放模型阵营中进一步逼近甚至对标顶级闭源模型的性能水平。









