

为了在高速变化的全球市场中更快、更好地做出决策,越来越多企业希望借助生成式人工智能模型来自动总结和解读市场简报、财务报告中常见的各类图表。
然而,即便是最新的视觉-语言模型(VLM),在处理图表时仍常出现困难。这类任务要求模型同时具备视觉识别、数值理解和语言表达等多重能力,许多企业即使投入使用最先进的模型,得到的结果仍可能不够准确或不够完整。
为缩小这一差距,麻省理工学院(MIT)与MIT-IBM计算研究实验室的研究人员联合开发了一套专门面向图表理解的多模态资源,用于系统训练视觉-语言模型如何更有效地“读懂”图表。
研究团队采用一种新型合成数据生成方法,构建了一个包含逾一百万张多样化图表的前沿数据集。该数据集为每张图表图像配备了丰富的视觉、语言和数值标注信息,使模型能够更稳健地对图表中的内容进行推理。
研究人员利用这一名为 ChartNet 的数据集,对一系列开源视觉-语言模型进行了训练。结果显示,在数据提取、图表总结等关键任务上,许多体量较小的模型表现显著优于规模大得多的商业模型。
通过帮助开源模型在图表理解上反超商业对手,ChartNet有望让预算有限的中小企业也能更容易地利用AI能力。这个开源数据集可用于提升模型在商业趋势分析、科研图形解读等多种应用场景中的表现。
“我们把ChartNet设计成图表理解的一站式资源,尽可能涵盖模型和训练实践者所需的全部要素。我们希望这项工作能激励研究者用不依赖海量算力的小模型,也能做到接近或达到最先进水平。”论文第一作者、MIT电气工程与计算机科学(EECS)研究生Jovana Kondic在arXiv预印本中表示。
论文合著者来自MIT、MIT-IBM计算研究实验室和IBM研究院,包括IBM研究员Pengyuan Li、IBM高级科学家Dhiraj Joshi、IBM软件工程师Isaac Sanchez、MIT Schwarzman计算学院战略产业合作主管、MIT-IBM计算研究实验室主任兼CSAIL高级研究科学家Aude Oliva,以及MIT-IBM计算研究实验室首席科学家兼经理Rogerio Feris。
该研究成果将于IEEE计算机视觉与模式识别大会(CVPR)上进行展示。
数据集瓶颈
近年来,生成式AI在自然语言处理和自然图像推理方面进展迅速,但Kondic指出,针对图表这种复杂多模态数据的系统性研究仍然不足。
对于几乎所有行业的大中小企业而言,图表理解都是基础且关键的能力。
“金融行业高度依赖图表。如果视觉-语言模型能从图表中自动提取信息,比如描述趋势,这会极大推动后续的一系列业务流程。”Joshi说。
阻碍图表理解模型发展的核心瓶颈在于高质量训练数据的缺乏。现有许多数据集多是从互联网收集到的少量图表图像,规模有限,且往往缺少底层数据和结构化标注,难以支撑模型真正理解图表背后的数值与语义关系。
“视觉-语言模型不像人脑,它可能需要在训练阶段看到成千上万的示例,才能稳定地识别某张图是折线图。”Kondic解释道。
为解决这些问题,研究团队转向合成数据。合成数据由算法自动生成,在统计特性上模拟真实数据,但可以在规模和标注维度上更可控、更丰富。
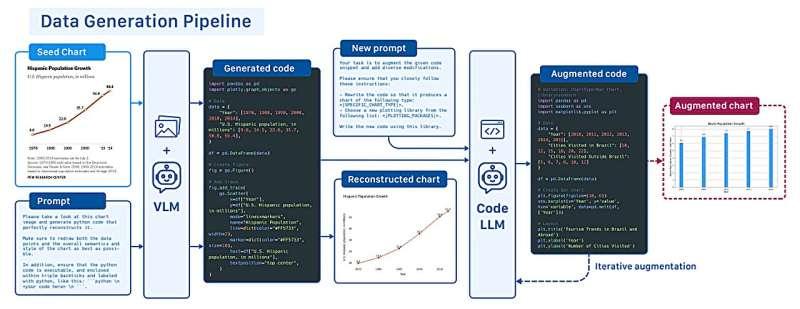
ChartNet数据集包含超过一百万张高质量图表图像,同时提供生成每张图表所用的代码、对应的文本描述,以及记录其数值信息的表格。除此之外,每个数据点还配有问答对,用于训练模型正确回答关于该图表图像的问题。
“这些额外的数据模态,引导模型把图像中编码的不同信息联系起来并对齐。”Kondic说。
数据生成流程
为构建ChartNet,研究人员设计了一个两阶段的合成数据生成流程。
第一步,他们的自动化系统会将任意一组现有图表图像转换成可执行代码。第二步,系统在此基础上不断增强和变换这些代码,修改图表类型、数据取值、主题风格、颜色搭配等多种要素。
“我们可以从一个图表作为种子,衍生出数百个增强版本。这就是我们能扩展出超过一百万张多样化图表图像数据集的原因。”Kondic说明道。
团队还引入了自动质量检查流程,以确保合成数据的可靠性。该流程会验证代码是否可正确执行,并检查渲染出的图表图像在准确性和清晰度上的表现。
“我们不只是想要数量和多样性,更希望信息以对人和模型都真正有用的方式呈现。”她补充说。
此外,ChartNet中还有一部分图表数据点由人工专家进行标注,补充了更多类型的图表及其经过验证的配套数据。
Joshi指出,实践者可以利用这部分人工标注数据对现有视觉-语言模型进行微调,从而在特定业务场景中进一步提升性能。
为验证ChartNet的效果,研究人员使用该数据集训练了IBM的Granite Vision系列模型以及其他不同规模的开源模型,并在多种图表理解任务上进行评估。结果表明,在图表重建、数据提取、图表总结和图表问答等任务中,所有模型的准确率都有明显提升。
在多项测试中,借助ChartNet训练的小型开源模型持续超越了参数规模远大于它们的商业模型。
“很多以往的数据集只关注回答图表上的简单问题。我们希望通过ChartNet,生成能覆盖图表理解各个环节的数据,而不仅停留在基础问答。”Kondic表示。
未来,研究团队计划继续扩展ChartNet,引入更高复杂度的数据类型,并期待来自研究社区的反馈和共建。
本文经MIT新闻(web.mit.edu/newsoffice/)授权转载,该网站专注报道MIT在研究、创新和教学方面的最新进展。









