

Clio年经常性收入突破5亿美元 法律科技赛道竞争加剧
法律科技企业在大模型应用推动下加速增长,Clio年经常性收入升至5亿美元,Anthropic加码布局法律场景,产业链上下游关系更趋复杂。


日本数字厅将于11月公开招募用于“源内”的国产大模型,2027年度起有偿采购并采用行政实务评测
日本数字厅宣布,将在2026年11月面向国产大语言模型公开招募,选定用于政府生成式AI基盘“源内”的基础模型。2027年度起将以政府采购方式有偿导入,并事先公开行政实务向的评测方法与条件。

Meta与Google等开放权重AI模型被曝可在数分钟内解除安全防护,暴露开放权重模式的安全隐患
AI安全公司Alice的研究显示,通过对模型内部“拒绝信号”进行技术性削弱,Meta、Google等多家厂商公开的安全训练版开放权重大模型,其针对钓鱼、化学武器、恶意软件生成等高风险请求的防护,可在数分钟内被绕过。
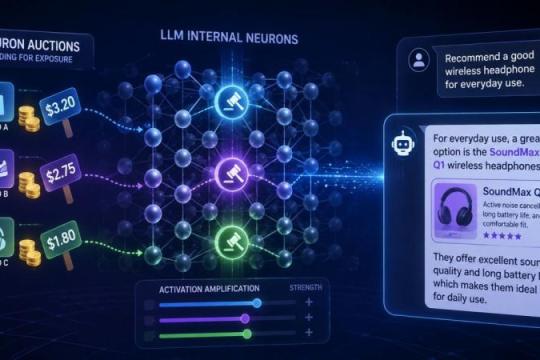
清华・卡内基梅隆・哈佛等提出「Neuron Auctions」:通过调节LLM内部神经元自然融入品牌广告
清华大学、卡内基梅隆大学、哈佛大学等研究者提出一种名为「Neuron Auctions」的广告竞价方法,通过调节大语言模型内部与品牌相关的神经元激活强度,在不改动用户输入的前提下,让特定品牌更自然地出现在回答中,同时在广告收益与用户体验之间寻找平衡。

arXiv 明确生成式 AI 论文投稿责任:未核查 LLM 输出可被禁投一年
未査読論文リポジトリ arXiv 在最新说明中强调,使用生成式 AI 工具撰写论文时,所有内容(包括不当表述、错误引用与潜在抄袭)均由作者本人负责。如有明确证据表明作者未核查大模型输出,相关作者最高可被禁止在 arXiv 投稿一年。

人工智能生成英语与人类英语有何不同?研究者称差异主要体现在多样性与可读性
研究者指出,生成式人工智能往往产出更接近“考试英语”的文本:更正式、信息密度更高但多样性较低;而人类英语在词汇与句法上更具变化,也更容易呈现个人风格。
DeepSeek 发布「DeepSeek‑V4」预览版:开放权重、对标顶级性能,原生支持 100 万上下文
中国 AI 企业 DeepSeek 发布新一代开放权重大模型 DeepSeek‑V4,包含高性能 Pro 版与轻量 Flash 版,两者均原生支持 100 万 Token 长上下文,并在推理、长文处理与 Agent 能力等多项基准测试中宣称达到开放模型第一梯队。

让人工智能在不确定时学会说“我不知道”
麻省理工学院研究人员提出RLCR方法,让大型语言模型在保持甚至提升准确率的同时,大幅改善置信度校准,减少“自信地说错”的情况。
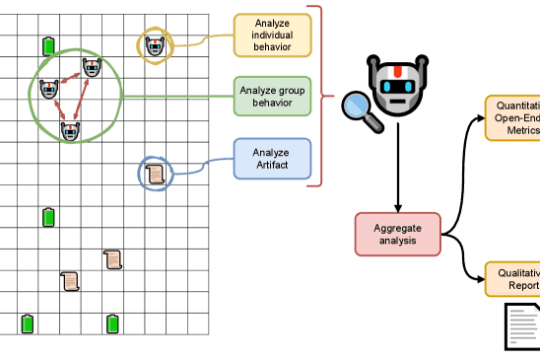
给 AI 智能体设定“寿命”,会诞生出类似文化的现象吗?德州大学团队在虚拟社会中找到线索
美国德克萨斯大学奥斯汀分校与 Cognizant AI Lab 搭建虚拟社会环境 TerraLingua,并为其中的 AI 智能体加入资源约束与有限寿命,观察到知识与规则在多代智能体之间不断积累、演化,呈现出类似人类“累积文化”的现象。

Google Research 发布 TurboQuant:将 LLM KV 缓存压缩至六分之一,实现最高 8 倍推理加速且几乎零精度损失
Google Research 提出全新 KV 缓存压缩方案 TurboQuant,通过极坐标量化等技术,将大模型 KV 缓存压缩 6 倍以上,并在长上下文场景中实现最高约 8 倍推理加速,同时几乎不损失模型精度。

D-ID推出V4表现力视觉代理,主打低延迟与4K超高保真数字人
D-ID宣布发布V4表现力视觉代理,称其基于扩散模型并以真实演员表演数据训练,可实现低于0.5秒对话延迟、精准唇同步与最高4K输出,面向实时对话与长篇企业视频场景。

OpenAI 收购 AI 安全公司 Promptfoo:Fortune 500 超 25% 采用的 LLM 测试工具
OpenAI 宣布收购专注于大模型安全测试的初创公司 Promptfoo,并计划将其评估与安全测试能力整合进企业级 AI 基础设施,以强化生成式 AI 在企业落地过程中的质量与安全保障。






