

Google DeepMind 于 2026 年 4 月 14 日(当地时间)发布面向机器人的视觉语言模型(VLM)「Gemini Robotics-ER 1.6」。新版本重点强化空间推理、多视角(Multi-view)理解以及任务成功判定等能力,并已通过 Gemini API 和 Google AI Studio 向开发者提供预览版。
面向机器人的「推理优先」视觉语言模型
Gemini Robotics-ER 1.6 是 Google DeepMind 所定位的「reasoning-first(推理重视)」机器人模型的最新版本。作为融合视觉与语言的 VLM,它被设计为机器人理解现实世界场景、并据此做出行动决策的基础模型。
与传统更偏重于识别「看到了什么」的视觉模型不同,ER 系列更强调在给定情境下「应该做什么」的推理能力,相当于为机器人提供决策层的大脑。
大幅强化空间推理与多视角理解
在 ER 1.6 中,模型对三维空间的理解能力得到显著提升。不仅能处理单一视角,还可以整合来自多台摄像头或多个视点的信息,实现对环境的「多视角理解」。
借此,机器人能够更精细地把握物体之间的空间关系、距离与遮挡情况等。现实环境往往存在噪声与信息缺失,多视角融合可以在此基础上提升整体感知精度。
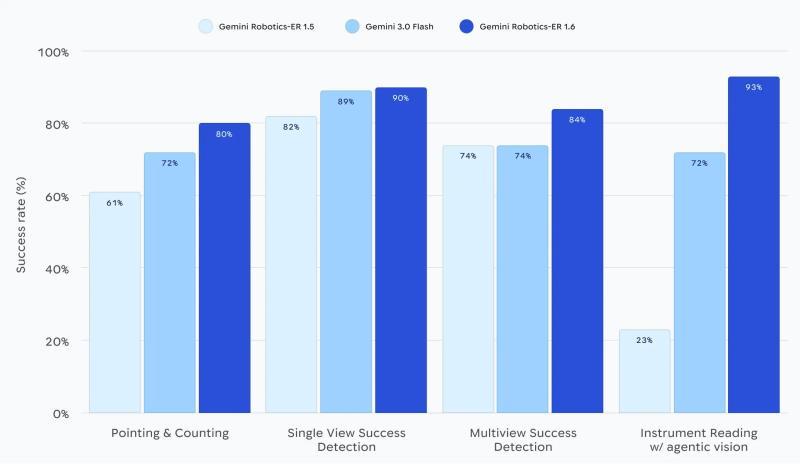
Gemini Robotics-ER 1.6 在多项任务上均优于前一代模型以及 Gemini 3.0 Flash
新增仪表读数与任务成功判定等实用功能
ER 1.6 新增了对仪表盘、显示屏等各类计量设备的读数能力。机器人可以从这些设备中读取数值或状态信息,并据此做出相应判断和决策。
DeepMind 表示,这一仪表读数功能源自与美国机器人公司 Boston Dynamics 的合作场景。例如,其四足机器人「Spot」可以在设施内巡检,通过摄像头采集仪表画面,并由模型进行解析和状态判断。
@YouTube
此外,模型对「任务是否成功完成」的判定能力也得到加强。它不仅执行动作,还能对结果进行评估,并将反馈用于后续行动规划,这对于提升真实环境中的自律性尤为关键。

在工具架识别任务中的对比。ER 1.6 在物体检测与分类精度方面均有提升

从自然语言到机器人动作:任务分解与执行支持
ER 1.6 能够将自然语言指令分解为可执行的步骤,并转化为具体的机器人动作。即便是较为复杂的指令,也可以拆解为多阶段流程,逐步完成。
同时,模型支持调用外部工具,并可与机器人控制系统集成,不仅是一个理解模型,更被设计为可直接驱动现实世界行为的「物理代理(physical agent)」。
通过 Gemini API 与 AI Studio 面向开发者开放
Gemini Robotics-ER 1.6 以预览版形式,通过 Gemini API 和 Google AI Studio 提供。开发者可以通过 API 调用该模型,并将其集成到各类机器人应用中。
模型以「gemini-robotics-er-1.6-preview」为名称提供,相关定价与使用说明已在面向开发者的文档中公开。与仅停留在研究阶段的模型不同,ER 1.6 从一开始就以可落地实施为目标进行发布。
相比前一代「ER 1.5」的主要升级
上一代「Gemini Robotics-ER 1.5」为机器人提供了以身体性为前提的推理能力,奠定了空间理解与任务规划的基础。
在此之上,ER 1.6 进一步强化了多视角理解、任务成功判定以及仪表读数等更贴近实际应用的功能,体现出从研究验证向实际部署与运营阶段过渡的趋势。
机器人 × VLM:迈向「物理世界 AI」
此次发布展示了生成式 AI 从纯数字空间向物理世界延伸的方向。将视觉、语言与行动统一到一个模型中,使其逐步成为机器人决策的核心基座。
在机器人研发领域,以大模型为中心的「基础模型」架构正在形成。未来,越来越多的机器人应用将基于此类通用模型进行二次开发与场景适配,加速「物理世界 AI」的落地。









