

Google于2026年1月27日宣布,在其AI模型「Gemini 3 Flash」中新增高精度图像理解功能「Agentic Vision」。与传统“一次性解析图像并直接回答”的方式不同,Agentic Vision让模型能够主动规划处理步骤,在需要时对图像进行放大、裁剪和重新检查,从而基于更充分的视觉证据给出回答。
Agentic Vision目前通过 Google AI Studio 和 Vertex AI 的 Gemini API 提供,现阶段被定位为 Gemini 3 Flash 专属功能。
从“一次性识别”到“分阶段验证”的图像理解
Agentic Vision 的核心特点,是将图像理解从静态的一次性识别,转变为多轮、可回溯的验证过程。模型不会在首次看到图像时就立即给出最终答案,而是会反复执行以下循环:
- 判断需要重点检查的图像区域
- 选择并执行相应的操作(如放大、裁剪、重新解析)
- 观察操作结果,再决定下一步行动
Google将这一过程概括为「Think(思考/规划)→ Act(行动/执行)→ Observe(观察/再判断)」的循环推理框架。
视觉推理与 Python 代码执行的深度结合
在技术实现上,Agentic Vision 的中枢是“视觉推理 + Python 代码执行”的一体化设计。
图)Agentic Vision 的处理流程:在接收到用户输入(图像 + 文本)后,AI 代理会围绕「Think(计划)→ Act(代码执行)→ Observe(结果确认)」不断循环,对图像进行放大、裁剪、标注等操作。Gemini 3 Flash 将基于 Python 的图像处理能力直接嵌入推理过程之中。
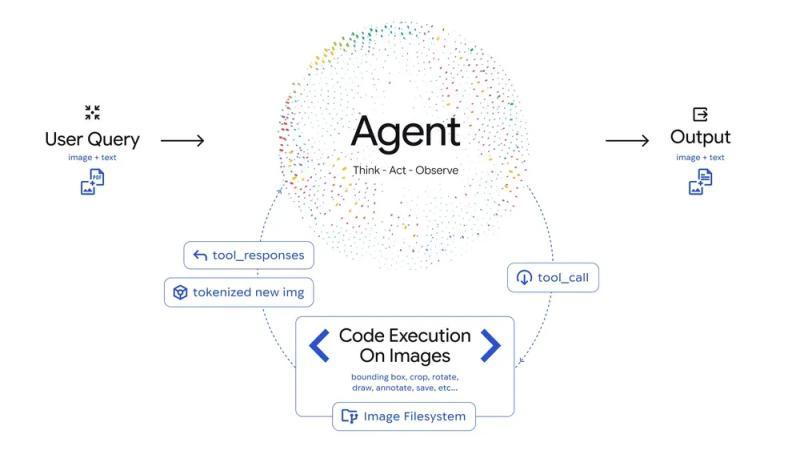
在 Agentic Vision 中,模型可以自主生成并执行 Python 代码,用于完成例如:
- 裁剪并放大图像的局部区域
- 对特定区域进行二次或多次解析
- 从图像中提取数值数据并进行计算
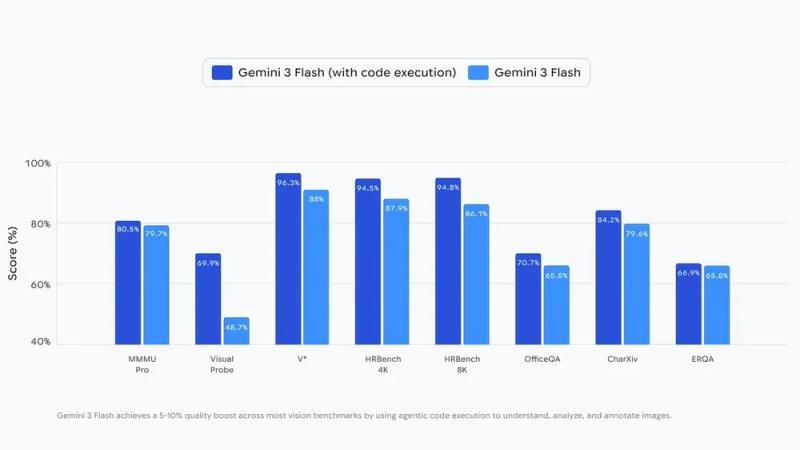
通过在代码执行环境中完成这些操作,模型的推理过程变得更加严谨,有助于减少误识别。根据 Google 的说明,在多项视觉相关基准测试中,引入这一机制后,整体质量提升约 5〜10%。

图)Agentic Vision 对视觉基准测试性能的影响:在 Gemini 3 Flash 中启用代码执行(with code execution)的配置后,在多数图像理解类基准测试中,得分较传统配置提升了约 5〜10%。Google认为,将图像的再检视和标注过程纳入推理链条,是精度提升的关键因素之一。
放大、标注与可视化:Agentic Vision 能做什么
从功能上看,Agentic Vision 主要带来了以下三类能力:
- 放大与再检视:当模型检测到存在小字号文字、远景目标等初次解析不充分的内容时,会主动放大相关区域并重新分析。
- 直接在图像上标注:模型可以在图像上绘制边界框、添加标签,明确标出目标的位置和数量,从而让回答的视觉依据更加直观可见。
- 视觉信息的计算与图表化:对于图像中的表格或数值信息,模型不仅能读取,还可以进行计算处理,并将结果以图表形式输出。
这些操作均由模型在推理过程中“按需触发”,即当模型判断有助于提高答案可靠性时,才会自动执行相应步骤。
在 Google AI Studio 与 Vertex AI 中提供,现为 Flash 专属
开发者可以在 Google AI Studio 以及 Vertex AI 的 Gemini API 中使用 Agentic Vision。只需在调用时启用代码执行功能,即可将这一针对图像的多阶段验证流程集成到自己的应用中。
根据官方文档,目前 Agentic Vision 仅面向 Gemini 3 Flash 提供,尚未开放给其他 Gemini 系列模型。
面向业务场景的高可靠图像理解
Google 将 Agentic Vision 定位为“面向业务使用的高可靠图像理解能力”,而不仅仅是单纯提升图像识别精度的技术升级。
在实际应用设想中,Google 特别提到以下场景:
- 读取仪表盘、仪器上的刻度与数值
- 解析以图片形式保存的表格数据
- 进行数量核对、盘点等对准确性要求极高的任务
通过引入“多轮验证 + 代码执行”的机制,Google 试图让 Gemini 3 Flash 在这些对精度和可解释性要求较高的业务场景中,提供更值得信赖的图像理解能力。









