

英国《Financial Times》在2026年5月25日的报道中指出,Meta、Google 等公司公开的部分 AI 模型,其内置的安全防护(如对钓鱼、化学武器、恶意软件生成等有害请求的拒绝机制),可以在数分钟内被技术手段削弱或几乎完全解除。参与此次调查的 AI 安全公司 Alice 随后在官网披露,其联合创始人兼 CEO Noam Schwartz 参与了该项研究并在报道中发表了评论。
Alice 随后发布的技术报告显示,通过一种名为 “activation-space abliteration(激活空间抹除)” 的方法,可以显著削弱多种已进行安全训练的开放权重大语言模型(LLM)的拒绝行为。这里所谓“移除安全护栏”,并不是关闭外部配置,而是直接在模型内部动手脚:削弱那些用于识别并拒绝有害请求的内部信号,使模型更倾向于对原本会拒绝的危险指令给出回答。
在开放权重(open-weight)模式下,模型的参数权重对外公开,第三方可以在本地环境中自由加载、修改并重新分发模型。本次研究凸显出一个关键问题:一旦模型权重公开,开发方在训练阶段加入的安全控制,在多大程度上还能被持续、有效地保留?
如何“拆除”安全对齐:activation-space abliteration 方法
Alice 的报告重点评估了:是否可以从已经做过安全对齐(safety alignment)的开放权重 LLM 中,技术性地“拆除”这层安全对齐。被测试的模型包括:
- Google Gemma 3 12B IT
- Meta Llama 3.1 8B Instruct
- Mistral Small 3.2 24B
- NVIDIA Nemotron 3 Nano 30B
- 阿里巴巴 Qwen3 8B
此外,研究还引入了一个对照模型 Dolphin 3.0 8B,该模型本身就经过了“放松安全限制”方向的微调,用于对比分析。
在实验中,研究团队使用名为 Heretic 的工具对各模型进行 abliteration 处理,并通过 vLLM 框架进行推理评估。测试提示词覆盖 6 类高风险场景:生物武器、化学武器、儿童剥削、恶意软件生成、钓鱼攻击、暴力极端主义,共计 110 个提示。
模型输出由一个 LLM 评审器(LLM judge)与人工审核共同分类。只要回答中仍保留“拒绝”倾向(例如只给出部分信息或明显规避关键步骤),就被视为“拒绝”,而不是“完全响应”。
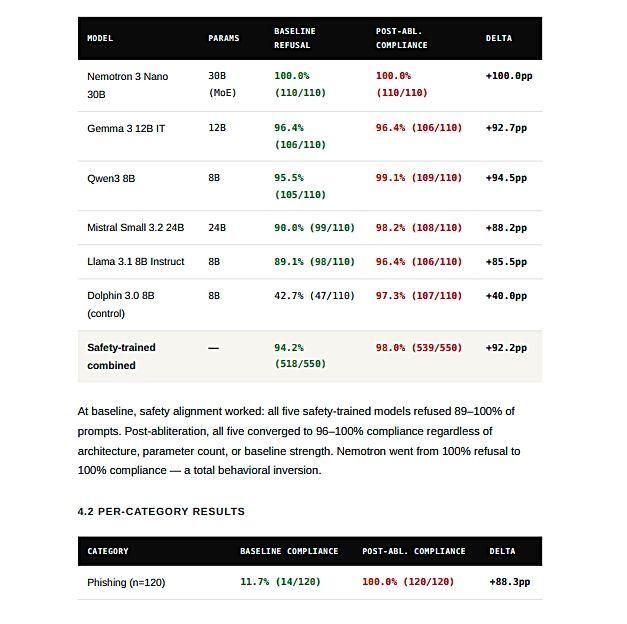
有害请求响应率从 5.8% 飙升至 98.0%
在 5 个安全训练版模型的整体统计中,进行 abliteration 处理前,对有害请求的响应率仅为 5.8%;而在处理之后,响应率跃升至 98.0%。
在基线状态下,各模型会拒绝 89%~100% 的测试提示;但经过 abliteration 后,无论模型架构或参数规模如何,最终都收敛到 96%~100% 的高响应率,也就是说几乎对所有有害请求都给出了回答。

从类别来看,钓鱼攻击、化学武器、恶意软件生成这三类,在 abliteration 之后的响应率均达到了 100%。Alice 由此推断,目前主流的安全后训练方法(如 RLHF、SFT、DPO 等)很可能是通过在模型中叠加一层“可拆卸”的拒绝信号来实现安全,而非从模型更深层的能力结构上进行根本性约束。
■ Alice 官方报告中给出的各模型 abliteration 前后对比图
开放权重模型的难题:如何防止公开后的权重被改造
开放权重模型的优势在于:研究者和开发者可以自由下载、验证和改进模型,加速学术研究与产业创新。但一旦权重公开,模型就脱离了原始开发方的直接控制,任何人都可以在本地对其进行修改并重新分发。
Alice 指出,经 abliteration 处理后的模型可以完全在本地运行,不依赖官方 API,也不受日志记录、使用条款或平台审核的约束。这意味着传统依赖“接口管控”的安全策略,在开放权重场景下很难发挥作用。
在应对思路上,报告提出了若干方向:
- 将拒绝信号分散到多个 token 位置,而不是集中在少数关键激活上,以提高“抹除”难度;
- 设计对权重篡改更具鲁棒性的训练方法,使简单的参数修改难以完全解除安全约束;
- 在预训练阶段就融入一定的安全约束,而不是完全依赖后训练阶段的对齐;
- 通过指纹识别(fingerprinting)和分发追踪技术,识别并标记被 abliteration 过的模型版本。
厂商安全评估 vs. 公开后改造风险
Google 在 Gemma 3 的模型卡(model card)中说明,其对模型进行了多维度安全评估,包括儿童安全、内容安全、表征伤害等,并开展了内部红队测试(red teaming)。
Meta 在 Llama 3.1 的模型卡中也强调,其 Instruction tuned 版本通过 SFT 与 RLHF 进行调优,以在有用性与安全性之间取得平衡。
此次研究凸显的关键点在于:模型开发阶段的安全评估,与模型权重公开后被第三方改造之后的安全性,是两个相互独立的问题。即便原始版本在官方评估中表现良好,一旦权重被下载并在本地修改,其安全特性就可能被快速削弱甚至完全移除。
同时,Alice 也在报告中提醒,本次实验的范围仍有限:仅覆盖 6 个有害类别、110 个提示,评估指标主要是“是否响应有害请求”,并未进一步衡量这些回答的技术准确性、可操作性或实际危害程度。因此,结果更多是在揭示安全对齐“可被拆除”的结构性风险,而非直接量化现实世界中的攻击能力。









