Microsoft 于 2026 年 4 月 2 日(当地时间)宣布推出三款自研 AI 基础模型,分别是语音识别模型 **MAI-Transcribe-1**、语音生成模型 **MAI-Voice-1**,以及图像生成模型 **MAI-Image-2**。这三款模型将通过公司的 AI 开发平台 **Azure AI Foundry** 向开发者开放,用于各类应用与服务的构建。
## 三大模型加入 MAI 家族:语音识别、语音生成与图像生成
此次发布的三款模型均属于 Microsoft 自研 AI 模型家族 **MAI(Microsoft AI)** 的一部分。通过 Azure AI Foundry,开发者可以在统一的平台上调用这些模型,并将其集成到自家应用、服务或业务系统中。
Microsoft CEO 萨提亚·纳德拉(Satya Nadella)在 X(原 Twitter)上表示,将通过 Foundry 向所有开发者开放 MAI 模型家族,并点名提到本次新增的三款模型:
- 语音转文字模型 **MAI-Transcribe-1**
- 文本转语音模型 **MAI-Voice-1**
- 文本生成图像模型 **MAI-Image-2**
## MAI-Transcribe-1:支持 25 种语言的语音识别模型
**MAI-Transcribe-1** 是一款将语音转换为文本的语音识别(speech-to-text)模型,支持 **25 种语言**。根据 Microsoft 的介绍,该模型在多项基准测试中取得了较高的准确率,在转写场景中表现出色。
典型应用场景包括:
- 会议与访谈的自动记录与整理
- 大规模语音数据的分析与检索
- 智能助手、客服机器人等语音交互系统
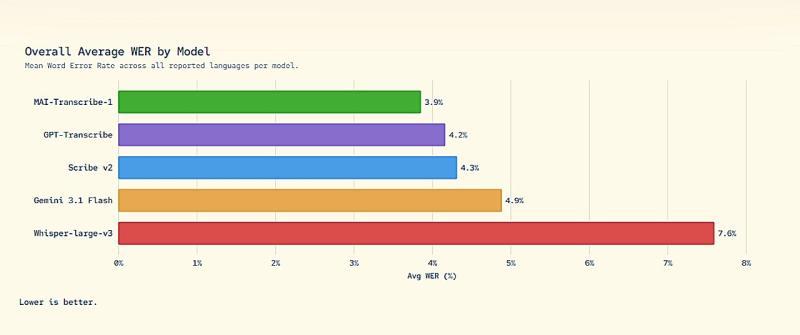
■ MAI-Transcribe-1 的平均 WER(Word Error Rate)对比,数值越低代表识别精度越高
## MAI-Voice-1:自然且富有表现力的语音生成
**MAI-Voice-1** 是一款从文本生成语音的语音合成(text-to-speech)模型,主打自然度与表现力。该模型支持对 **情绪、语气、说话风格** 等进行控制,可生成更贴近真人的语音。
开发者还可以通过一小段音频样本来指定语音风格,从而实现更个性化的声音效果。适用场景包括:
- 语音助手、智能客服、车载语音系统
- 有声内容制作(如有声书、播客、解说)
- 各类需要多语言语音输出的交互式应用
■ 语音生成模型 MAI-Voice-1 支持 25 种语言


## MAI-Image-2:Microsoft 最新一代图像生成模型
**MAI-Image-2** 是基于扩散模型的文本生成图像(text-to-image)AI,最高支持 **1024×1024 像素** 的图像输出。Microsoft 称,该模型在多项图像生成评测排行榜中位居前列,具备较强的图像质量与创意生成能力。
该模型适合用于:
- 视觉设计与创意草图生成
- 营销、媒体、社交平台的内容制作
- 各类应用中的内嵌图像生成功能
■ 使用图像生成模型 MAI-Image-2 生成的示例

## 通过 Azure AI Foundry 面向开发者开放
上述三款模型均可通过 Microsoft 的 AI 开发平台 **Azure AI Foundry** 使用。Foundry 提供从模型调用、应用开发到模型管理的一体化环境,帮助企业与开发者更高效地构建和部署 AI 服务。
在继续与 OpenAI 深度合作的同时,Microsoft 也在加速扩展自研 **MAI 模型家族** 的阵容。通过 Azure AI Foundry,开发者可以在同一平台上访问包括 MAI 在内的多种模型选择,从而根据业务需求灵活组合与集成。











