

MLCommons 作为专注于 AI 性能评测的行业联盟,于 2026 年 4 月 1 日正式公布了最新一轮推理性能基准测试「MLPerf Inference v6.0」的结果。此次评测覆盖了包括大规模语言模型(LLM)在内的多种生成式 AI 推理工作负载,共有 NVIDIA、AMD 等在内的 24 家组织提交了系统测试结果,为业界提供了 AI 服务器推理性能的对比依据。
在本轮版本中,MLPerf Inference 进一步扩展了评测范围,顺应生成式 AI 的快速普及,首次加入了用于衡量视频生成 AI 推理性能的「Text-to-Video」测试项目。
面向 AI 推理的行业标准基准测试
MLPerf Inference 是一套专门用于评估机器学习模型在实际部署环境中推理性能的基准测试套件,重点衡量推理速度与吞吐能力。它覆盖数据中心、公有云、本地部署以及各类边缘设备等多种场景,已成为评估搭载 GPU 或专用 AI 加速器服务器性能的重要行业参考标准。
在最新发布的 v6.0 中,MLCommons 根据 AI 基础设施的技术演进,对测试内容进行了更新与扩充。在面向数据中心的 11 个测试项目中,有 5 个为新增或经过大幅更新的测试,用以更好反映当前主流 AI 工作负载的需求。
NVIDIA 与 AMD 的 AI 服务器配置占据领先位置
MLPerf Inference v6.0「Llama2-70B Interactive」基准测试结果
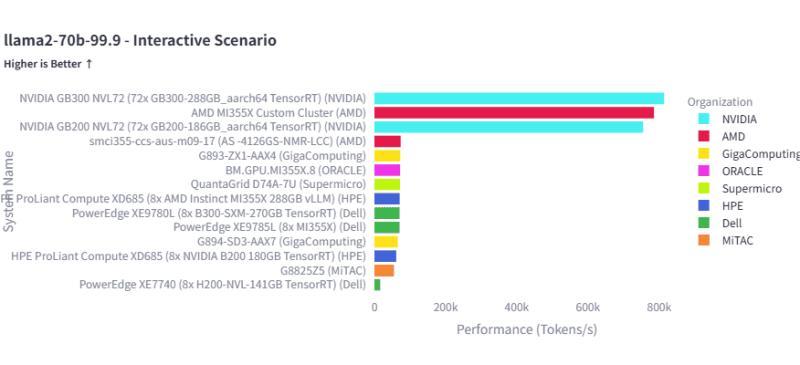
在本次公布的结果中,搭载 NVIDIA 与 AMD AI 加速器的服务器系统整体表现突出,在多个测试项目中位居前列。以 Llama2-70B 模型为基础的交互式推理测试中,采用 NVIDIA GB300 GPU 的系统以及基于 AMD MI355X GPU 集群的配置都展现出极高的推理性能。
这些结果为评估 AI 数据中心基础设施的处理能力、比较不同厂商与不同系统架构之间的差异,提供了量化的性能指标,便于用户在选型与架构设计时进行参考。
大规模 AI 模型推理能力持续提升
GPT-OSS-120B 模型的离线推理性能对比
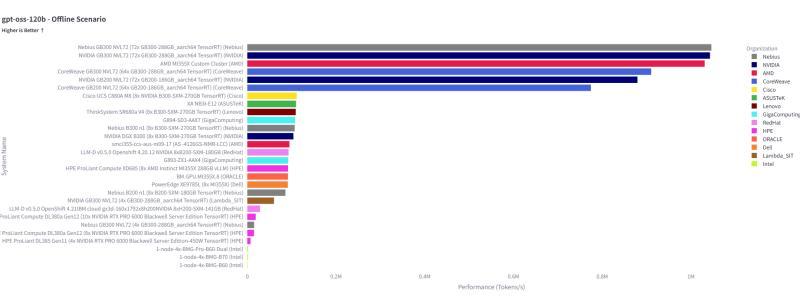
在针对大规模语言模型的推理测试中,多家机构提交了由数十到数百块 GPU 组成的大型服务器集群配置。以 GPT-OSS-120B 模型为例,在离线推理场景下,部分系统的处理性能已经突破每秒 100 万 token,显示出当前 AI 基础设施在大模型推理吞吐方面的显著提升。

这些数据不仅反映了硬件算力的增强,也体现了在模型优化、并行化策略以及系统软件栈方面的持续改进。
首次引入视频生成 AI 推理基准
MLPerf Inference v6.0 新增的「Text-to-Video」基准测试
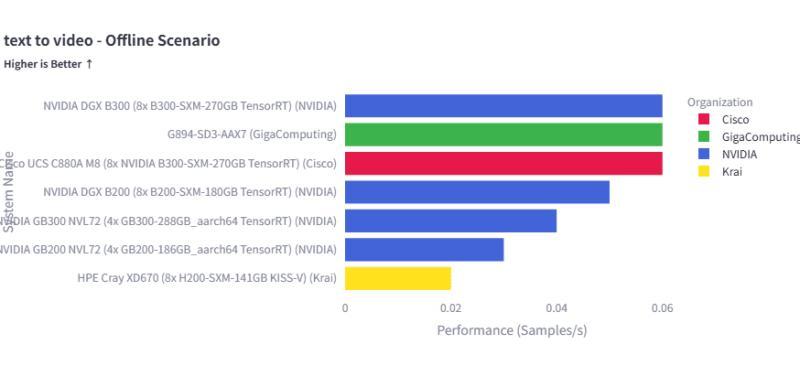
为顺应生成式 AI 的新趋势,v6.0 首次加入了面向视频生成模型的「Text-to-Video」推理基准,用于评估从文本描述生成视频内容的 AI 模型在推理阶段的性能。该测试基于阿里巴巴开发的视频生成模型构建工作负载,模拟真实应用中的生成流程。
测试结果显示,采用 NVIDIA B300、B200 等 GPU 的系统在该项目中名列前茅,表明在视频生成等更复杂、更重算力的生成式 AI 场景中,大规模 GPU 服务器依然是关键的基础设施形态。
结果通过在线仪表板公开
MLCommons 将本轮 MLPerf Inference v6.0 的全部测试结果通过在线仪表板对外开放。用户可以在仪表板中按提交组织、硬件配置、模型类型、工作负载场景等多种条件进行筛选与对比,查看不同系统在各项推理任务中的性能表现。
这一公开平台有助于研究机构、云服务商以及企业用户更直观地了解各类 AI 服务器与加速硬件的实际能力。
成为 AI 基础设施竞争的重要风向标
MLPerf 已被广泛视为衡量 AI 系统性能的行业标准基准之一,其结果常被用来评估 GPU 与各类 AI 加速器厂商的技术实力与市场竞争力。
随着生成式 AI 的快速发展,MLPerf Inference 持续将 LLM、视频生成模型等新型工作负载纳入评测范围,使其不仅是单纯的性能测试工具,也逐渐成为观察 AI 服务器与数据中心基础设施性能竞赛的重要风向标。









