

NTT于2026年5月19日宣布,在自家大模型「tsuzumi 2」的基础上推出升级版本「tsuzumi 2 Vision模型」。新模型可以将包含表格、图表、图形和流程图等内容的日文商务文档作为图片输入,在理解文档中文字信息的同时,综合利用其中的视觉信息进行回答。
面向图表类日文商务文档的 Vision 模型
在企业和政府机构的日常业务中,大量文档以表格、票据、报表、图表、流程图、演示文稿等形式存在,仅依靠纯文本难以高效处理。「tsuzumi 2 Vision模型」能够将这类文档以图片形式读入,并在理解文字内容的同时,结合版式布局、图表结构等视觉要素进行整体解析。
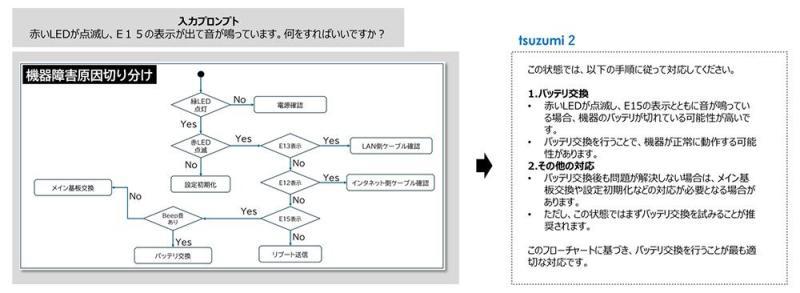
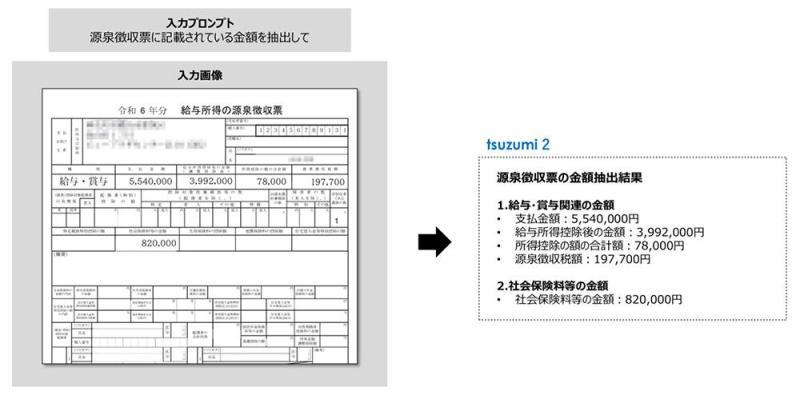
NTT给出的应用示例包括:在授信审查等业务中,从各类票据、表单中自动抽取必要字段;在技术支持场景中,理解用于故障原因判断的流程图等。未来还可用于从图表中抽取关键数据并结构化入库等场景。
单GPU即可运行,适配本地与私有云环境
「tsuzumi 2」是NTT自研的轻量级国产大语言模型,主打高性能与低资源占用。NTT早在2025年10月就以“高性能、高安全、低成本的纯国产LLM”为定位,正式对外提供该模型。
相比需要大量算力资源的超大规模LLM,企业在实际业务中更关注运维成本、能耗以及敏感数据的安全。「tsuzumi 2」以单GPU环境运行为前提进行设计,便于在无法将数据发送至外部API的场景中部署使用。
在金融机构、地方政府、医疗机构等领域,账单、申请表、诊疗记录和各类业务文档中往往包含大量个人隐私和机密信息。NTT表示,目前「tsuzumi 2」主要被用于本地部署或私有云环境中,围绕这类高敏感数据的处理需求展开应用。
强化数值处理等逻辑推理能力
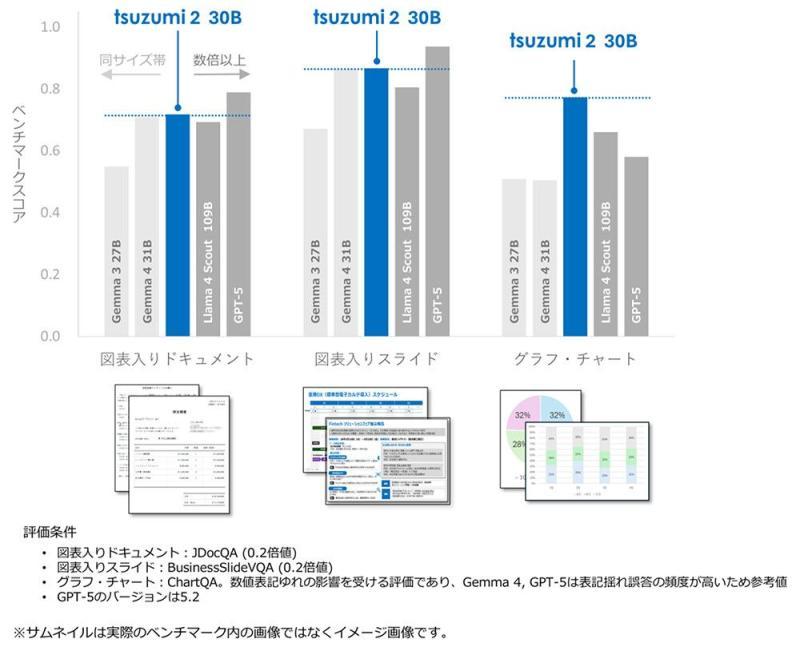
此次升级不仅加入了图表理解能力,同时也重点提升了包含数值计算在内的逻辑推理能力,以更好适配实际业务场景。
在商务文档中,模型需要准确理解表格中的数值、销售金额、条件分支、函数名称以及各字段之间的关系。NTT表示,新版本在销售金额等数值信息的理解与计算方面,以及对API文档等技术资料中函数含义的把握上,都达到了更高的水准。
NTT称,在以“图表丰富的日文商务文档理解”为目标进行优化后,「tsuzumi 2 Vision模型」在同等规模模型中达到了世界领先的性能水平。
推动国产LLM在企业级场景的落地
「tsuzumi 2」是NTT面向企业级应用打造的国产LLM,重点强化了日文处理能力与模型轻量化。在NTT R&D的技术介绍中,该模型被定位为面向法人客户、专注于RAG检索与摘要、信息抽取、文档总结等任务的基础模型。
此前的「tsuzumi 2」主要聚焦于以文本为主的日文文档处理和各类业务辅助任务。「tsuzumi 2 Vision模型」在此基础上进一步支持包含图表和复杂版式的文档图片,使AI能够覆盖更广泛的业务文档类型。
NTT计划通过NTT集团各子公司,逐步向客户提供此次升级后的「tsuzumi 2」及其Vision模型服务,加速国产LLM在金融、公共部门、医疗等高安全要求行业中的应用落地。









