
OpenAI 于 2026 年 4 月 22 日发布了专为临床工作设计的「ChatGPT for Clinicians」。这一工具将免费向美国经过认证的医务人员个人开放,首批适用对象包括医生、执业护士(NP)、医师助理(PA)以及药剂师。
OpenAI 表示,在医务人员被大量病历记录和不断增长的医学文献所压缩的现实下,希望通过该工具减轻其事务性负担,让临床人员能将更多精力投入到高质量的患者照护中。
面向美国认证医务人员的免费临床工作空间
ChatGPT for Clinicians 是一个为临床一线场景量身打造的全新 ChatGPT 工作空间。根据 OpenAI 的说明,目前美国境内通过认证的医生、NP、PA 和药剂师均可免费使用。未来,OpenAI 计划在符合各国监管要求的前提下,逐步扩展支持的国家和专业人群。
在此之前,OpenAI 已于 2026 年 1 月面向医疗机构推出「OpenAI for Healthcare」。后者主要帮助医院等机构,为院内临床医生、管理人员和研究者大规模部署具备合规与管理功能的 ChatGPT。与之相比,这次的 ChatGPT for Clinicians 更侧重于直接服务个人临床医生,而非以医疗机构为单位部署。
支持循证查证、文书撰写与医学研究
ChatGPT for Clinicians 集成了多项面向临床任务的能力,包括:
- 能够回答复杂临床问题的 AI 模型
- 支持重复性临床流程的「技能」(可复用工作流)
- 可信赖的临床检索功能
- 跨医学文献进行系统性检索的 Deep Research 功能
OpenAI 称,该工具可基于数百万篇经过同行评议的研究文献,实时给出带有出处标注的回答,用于辅助病例讨论和临床决策。
在具体应用上,例如撰写转诊信、处理事前授权(pre-authorization)、为患者撰写说明文书等任务,临床人员可以通过可复用的「技能」设定固定流程,让 ChatGPT 每次都按同样步骤执行,提升效率和一致性。
在医学文献综述方面,用户可以预先设定可信信息源,并在对话中不断调整检索方向,由 ChatGPT 生成带有清晰文献出处的综述报告,用于研究或临床决策支持。
此外,当医务人员使用 ChatGPT for Clinicians 针对临床问题进行文献和证据检索时,部分证据综述有可能被认定为 CME(继续医学教育)学分。OpenAI 强调,该工具并非用来取代医务人员的专业判断和知识,而是通过信息提供和整理来辅助临床决策。

通过医疗专用基准评估临床任务表现
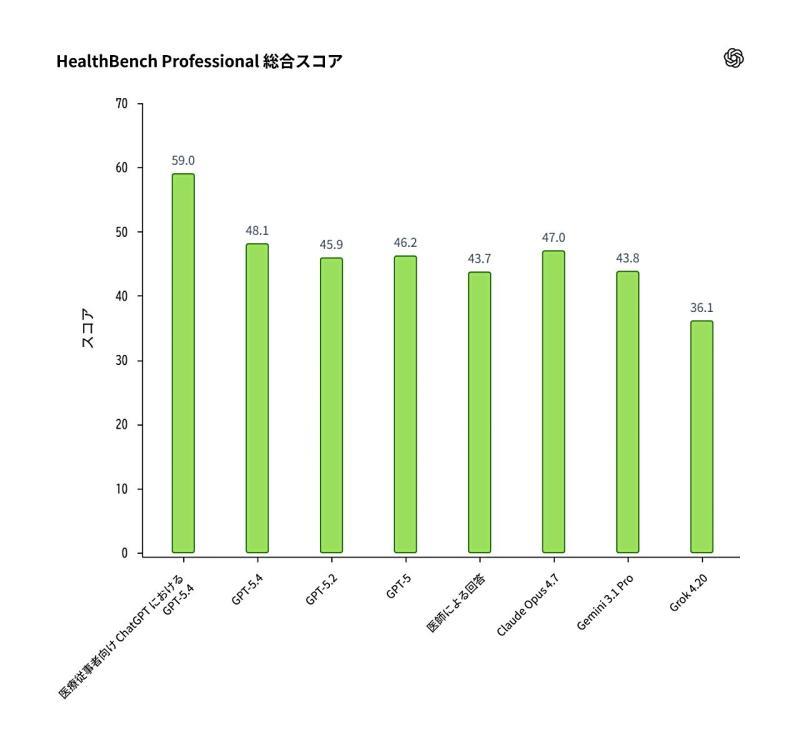
配合 ChatGPT for Clinicians 的发布,OpenAI 同时推出了新的评估基准「HealthBench Professional」。这一基准以医务人员在实际工作中向 ChatGPT 提出的真实任务为基础,用于衡量模型在临床场景下的表现。
在公开的综合评分中,面向医务人员优化的 GPT-5.4 在 HealthBench Professional 上取得了 59.0 分,表现优于 GPT-5.4(通用版本)、GPT-5.2、GPT-5、Claude Opus 4.7、Gemini 3.1 Pro、Grok 4.20 等模型。
该基准主要覆盖三大类临床使用场景:
- 患者照护咨询
- 文书撰写与病历记录
- 医学研究与文献检索
在这些场景中,模型需要完成真实的临床对话任务。
根据 OpenAI 的介绍,在正式发布 ChatGPT for Clinicians 之前,医师顾问团队基于临床照护、记录工作和研究等日常任务,对 6924 轮对话进行了验证。总体来看,其中 99.6% 的回答被医生评估为安全且准确。
在 HealthBench Professional 中,OpenAI 使用由医生编写的对话与评估标准,结合多轮医生判读和数据过滤,来衡量模型在一般临床对话中的性能与安全性。约三分之一的测试样本由医生刻意进行「红队测试」(red teaming),以主动挖掘模型在安全性和可靠性方面的潜在问题。
隐私保护与合规:不用于模型训练,可支持 HIPAA
OpenAI 表示,ChatGPT for Clinicians 中的对话内容不会被用于模型训练。工具本身配备了多因素认证等安全防护措施。
在需要处理受保护健康信息(PHI)的场景下,医疗机构可以与 OpenAI 签署业务伙伴协议(BAA),以启用符合 HIPAA 要求的使用模式,从而在隐私与合规方面满足美国医疗行业的监管标准。










