

Stability AI 于 2026 年 5 月 20 日正式发布新一代音乐生成 AI 模型家族「Stable Audio 3.0」。这家公司因开发图像生成模型「Stable Diffusion」而广为人知,如今则将 Stable Audio 3.0 定位为基于完全授权数据训练的音乐与音效生成模型系列。
在 Stable Audio 3.0 中,Stability AI 提供了面向不同用途的多种模型:用于生成音效的「Stable Audio 3.0 Small SFX」、用于生成短音乐片段的「Stable Audio 3.0 Small」、面向完整乐曲结构创作的「Stable Audio 3.0 Medium」,这三款模型都以开放权重(Open Weights)的形式提供。面向高质量音乐生成的「Stable Audio 3.0 Large」则通过 Stability AI 的 API 以及企业自托管(Self-hosting)方式提供。
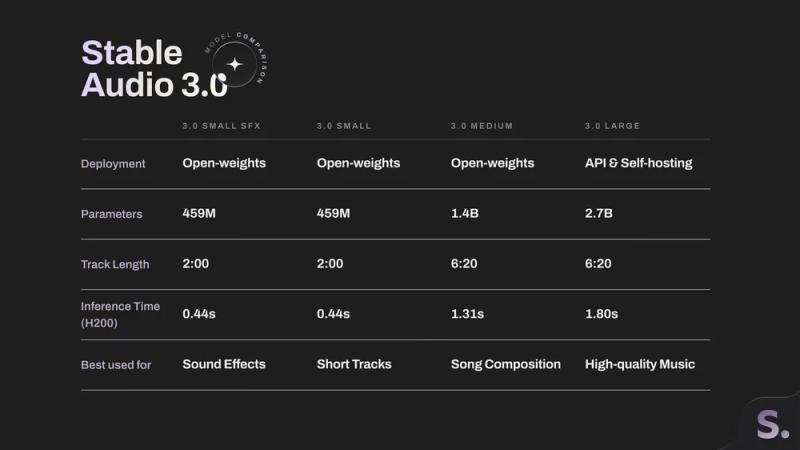
四种模型构成的 Stable Audio 3.0 系列
Stable Audio 3.0 由四个针对不同场景、以不同方式提供的模型组成。
其中,Small SFX 主要用于生成各类音效,Small 适合生成较短的音乐片段,Medium 则面向更完整的乐曲结构创作。这三款模型均以开放权重形式发布,方便开发者和创作者在本地或自有环境中使用。Large 模型则专注于高保真音乐生成,通过 API 和企业级自托管方式提供给需要更高质量和更大规模生成能力的用户。
在可生成音频时长方面,Small SFX 与 Small 最长可生成 2 分钟音频,Medium 与 Large 最长可生成 6 分 20 秒。用户可以根据需求,从音效制作、短音乐片段创作到更长篇幅的乐曲制作,选择合适的模型。
支持最长 6 分 20 秒的可变长生成,并可进行音频编辑
Stable Audio 3.0 是一组支持可变时长音频生成与编辑的潜在扩散模型(Latent Diffusion Models)。它采用全新的 semantic-acoustic 自动编码器(autoencoder),将音频映射到压缩的潜在空间中,在保持音质的前提下提升生成效率。
用户可以以秒为单位精确指定生成音频的时长,从短促的音效到数分钟的完整乐曲都能灵活输出。对于 Medium 和 Large 模型,单次生成的音乐时长上限为 6 分 20 秒。

Stable Audio 3.0 还支持音频 inpainting(音频补全/修补)。用户可以对已有音频的部分片段进行编辑,或基于一小段录音继续生成后续内容。因此,它不仅适用于从零开始创作音乐,也适合在已有素材基础上进行扩展和润色。
Small 与 Medium 模型已在 Hugging Face 上开放
Stable Audio 3.0 的 Small SFX、Small 和 Medium 模型已在 Hugging Face 上以开放权重形式发布。Small 与 Medium 被设计为在本地环境以及消费级硬件上也能较为轻量地运行,降低了使用门槛。
在 Hugging Face 上,除了提供 Stable Audio 3.0 Medium 的模型卡(Model Card)外,还发布了包含 Small SFX、Small、Medium 在内的 Stable Audio 3 模型合集。所有这些模型均基于 Stability AI Community License 授权发布。
基于完全授权数据训练,输出可用于商业用途
Stability AI 特别强调,Stable Audio 3.0 系列模型完全基于已获得授权的训练数据构建。根据 Stability AI Community License 或 Enterprise License 的条款,用户对模型生成的内容拥有所有权,并可以进行分发和商业化使用。
需要注意的是,年收入超过 100 万美元的组织将被归入 Enterprise License(企业许可)范围。当前,围绕音乐生成 AI 的训练数据来源与版权处理问题备受关注,Stability AI 将「完全授权数据训练」作为一大卖点,也是 Stable Audio 3.0 的重要特征之一。
计划支持 ComfyUI 等合作平台
Stable Audio 3.0 Large 目前可通过 Stability AI 的 API 使用,并支持企业级自托管部署,目标用户不仅包括研究人员和创作者,也涵盖需要在商业服务或专业制作环境中集成音乐生成能力的机构。
未来,Stable Audio 3.0 还计划在 ComfyUI 等合作平台上提供支持。以图像生成技术闻名的 Stability AI,正通过 Stable Audio 3.0 将其在开放权重、API 与自托管相结合的模型发布策略,扩展到音乐与音效生成领域。









