

在一篇最新论文中,圣菲研究所复杂性方向的博士后研究员张元钊与合著者威廉·吉尔平展示,一种看似朴素的预测策略,竟然能够在多种任务上超越当前领先的机器学习预测模型。
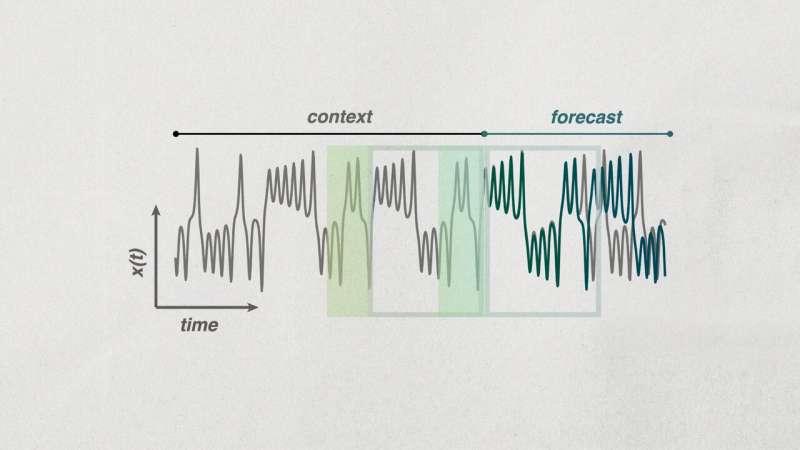
这项方法被称为“上下文复述”(contextual recurrences),核心思想是利用时间序列中的短片段作为“上下文”。在沿时间序列移动时,算法会不断扫描序列中过去已经出现过的相似模式或母题,并基于这些相似片段来推断接下来最有可能发生的变化。
张元钊指出,在评估人工智能系统的性能和智能水平时,研究人员需要保持谨慎态度,并持续尝试打开这些系统预测机制的“黑箱”。这篇论文正是对这一点的提醒:有时简单的基线方法就能达到甚至超过复杂模型的效果。
论文的三项主要贡献进一步支撑了这一观点:
-
提出强有力的零样本预测基线
研究首次系统性地提出“上下文复述”作为零样本预测(zero-shot prediction)的一种强大且出乎意料有效的基线方法。所谓零样本预测,是指在没有针对某个特定系统进行过专门训练的前提下,仅凭一小段观测数据就对该系统的未来行为做出预测。 -
在困难任务上超越主流模型
论文显示,这一简单策略在多种困难预测任务上表现优异,其中包括对混沌系统动力学的预测等传统上被认为极具挑战性的场景。在这些任务中,“上下文复述”方法在精度上可以超过多种当前主流的机器学习预测模型。 -
解释上下文长度与复杂性的关系
研究还给出了一个解释框架:随着提供给模型的上下文片段变长,预测准确率会随之提高,而这种提升的速度与被预测系统本身的复杂性密切相关。也就是说,系统越复杂,所需的上下文信息越多,预测性能的改善曲线也会有所不同。
这篇论文将于4月23日至27日在巴西里约热内卢举行的国际学习表征会议(International Conference on Learning Representations)上正式发表,目前已在 arXiv 预印本服务器上线,供研究社区提前阅读与讨论。









