

百科全书出版机构 Encyclopædia Britannica(下称“大英百科全书”)于 2026 年 3 月 13 日在美国纽约南区联邦地区法院起诉 OpenAI。根据起诉书内容,大英百科全书主张其百科全书与辞典内容被 OpenAI 未经授权使用,用于训练大规模语言模型以及检索增强生成(RAG)等用途,同时指控生成式 AI 的回答已经构成对其著作权和商标权的侵害。本案的争点不再仅限于“训练阶段的数据使用”,还进一步延伸到对“生成输出内容的责任”认定。
“知识基础设施”起诉 AI:传统百科与生成式 AI 正面冲突
原告大英百科全书是一家历史悠久的百科全书出版机构,长期在教育与参考工具领域扮演“知识基础设施”的角色。其子公司 Merriam-Webster 作为知名词典品牌,也一并列为原告。
早在 2012 年,大英百科全书就停止纸质百科全书的出版,全面转向数字化,被视为“知识在线化”的先行者之一。如今,这家率先完成数字转型的传统知识机构,因其在网络上积累的知识资产被用于 AI 模型而提起诉讼,引发外界高度关注。
争点升级:从“训练数据”到“生成内容”
在本次诉讼中,大英百科全书不仅质疑 OpenAI 在模型训练阶段对其内容的使用是否合法,更将矛头指向生成式 AI 的回答本身。
起诉书称,OpenAI 通过抓取(scraping)或复制等方式获取了大英百科全书及 Merriam-Webster 的内容,并将其用于大规模语言模型训练以及检索增强生成(RAG)系统。原告指出,ChatGPT 等工具在回答用户问题时,可能会以摘要、节选,甚至接近逐字重现的方式,输出与原始条目高度相似的内容。
例如,当用户就某一主题提问时,AI 可能在参考百科条目后,生成保留原有结构的回答:包括条目定义、背景说明、关键事件的时间顺序等。部分表述甚至可能与原文完全相同,或仅做极少量改写。
在原告看来,这已经超出了单纯“传递知识”的范畴,而是将特定编辑成果——包括文章结构与具体表述——反映在生成文本中。起诉书据此主张,这类输出行为本身就构成对著作物的利用,应受到著作权法约束。

■ 生成式 AI 通过参考外部数据生成回答的机制(引自起诉书)——争议焦点不仅在“训练”,也在“输出阶段”的使用
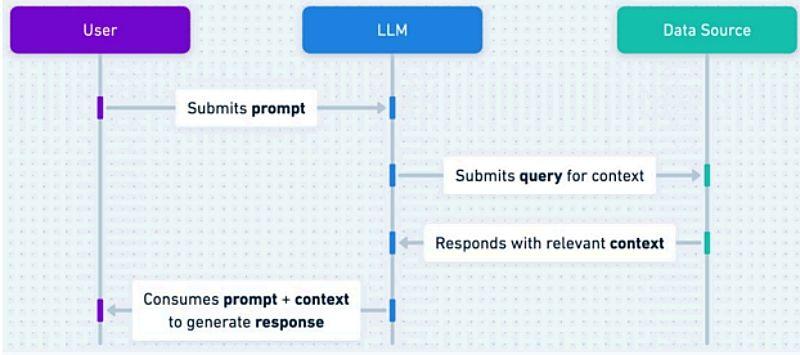
起诉书强调,与此前多起围绕生成式 AI 的诉讼主要集中在“训练数据是否合法使用”不同,本案进一步提出了“生成文本本身是否构成侵权”的新问题,可能对未来相关案件的判断标准产生影响。
商标与错误信息:品牌被“挂名”的风险
除著作权外,大英百科全书还在起诉书中主张 OpenAI 侵犯其商标权。
原告指出,当 AI 在回答中使用“大英百科全书”或“Merriam-Webster”等名称,并同时给出不准确或不完整的信息时,用户可能会误以为这些内容出自相关品牌或得到其背书。这不仅涉及内容本身的使用,更关系到品牌声誉与公信力的受损。
生成式 AI 在提供回答时,往往会附带“看似权威的出处”或引用方式,这在提升便利性的同时,也带来了另一种风险:一旦错误信息与知名品牌名称绑定传播,可能严重误导公众,对品牌造成长期负面影响。
原告请求禁令与损害赔偿
大英百科全书认为,相关侵权行为目前仍在持续,因此请求法院发布禁令,要求 OpenAI 停止对其内容的侵权使用。
同时,原告还依据著作权法请求法定损害赔偿,并要求赔偿实际损失、返还不当得利以及支付律师费等。若法院支持这些请求,本案可能成为生成式 AI 领域中,关于“训练利用”与“输出责任”双重维度的标志性判例。









