

微软于 2026 年 3 月 30 日宣布,为 Microsoft 365 Copilot 中的研究功能「Researcher」加入全新的多模型能力,可以组合使用多个 AI 模型来自动生成调研报告。通过同时利用 OpenAI 与 Anthropic 的模型,微软希望在事实准确性和分析深度上都有明显提升。
Researcher 是集成在 Microsoft 365 Copilot 里的一个深度调研 AI 代理(deep research agent),专门用于处理复杂的调查任务和报告撰写。此次更新的核心,是从过去依赖单一模型,升级为让多个模型分工协作的「多模型(multi‑model)」架构。
「Critique」:两套模型分工生成与审稿
新功能之一「Critique」采用双模型协作机制,让两个 AI 模型分别承担不同角色:
- 第一个模型负责调研规划、信息检索以及报告初稿撰写;
- 第二个模型则作为「审稿人」,对内容进行核查、结构优化和逻辑梳理。
微软表示,这种将「生成」与「评估」分离的设计,类似学术论文的同行评审流程,有助于系统性提升报告质量。
在审稿阶段,负责评估的 AI 主要从以下几个方面对报告进行检查:
- 信息来源是否可靠
- 报告内容是否足够全面
- 证据与引用是否恰当
通过这套流程,系统可以在事实准确性、分析深度以及行文结构等方面,对初稿进行改进,输出质量更高的调研报告。
借助 DRACO 基准测试验证效果
微软使用名为 DRACO(Deep Research Accuracy, Completeness, and Objectivity)的基准测试,对全新的 Critique 架构进行了评估。DRACO 覆盖医疗、技术、法律等 10 个领域,共 100 个复杂调研任务,从以下维度衡量 AI 的调研能力:
- 事实准确性
- 分析深度
- 表达与呈现质量
- 引用质量
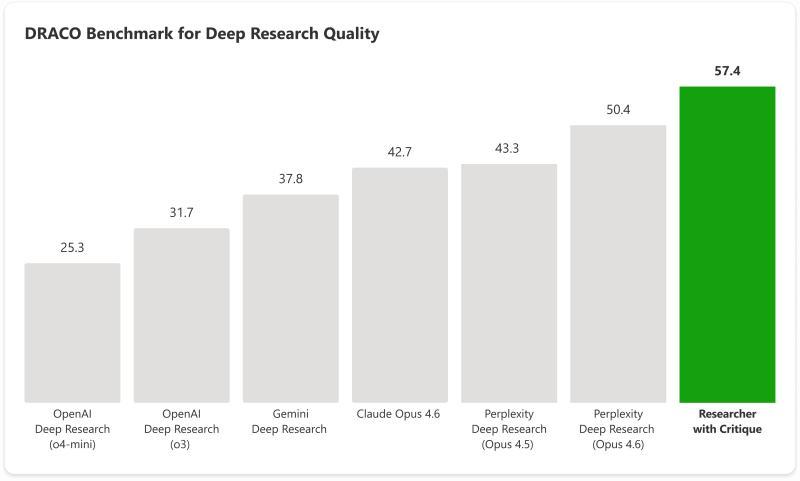
评估结果显示,采用 Critique 架构的 Researcher 在整体表现上优于传统的单模型方案,尤其在分析广度与深度、文本结构以及事实准确性等指标上有明显提升。
■ DRACO 基准测试中各类 AI 调研系统的比较。搭载 Critique 的 Researcher 取得最高分
「Council」:并行运行多模型并对比结果
另一项新功能「Council」则侧重于「多视角对比」。在该模式下,系统会同时运行多个 AI 模型:
- OpenAI 的模型与 Anthropic 的模型各自独立生成一份报告;
- 随后,由专门的判定模型对两份结果进行比对和评估。
判定模型会整理出:
- 两者的共识部分
- 存在分歧的观点
- 各模型独有的视角与侧重点
最终,系统会生成一份总结性报告,帮助用户快速理解不同模型之间的分析差异与解读偏好,从而获得更全面的参考视角。
通过 Frontier 计划率先提供
目前,「Critique」与「Council」已通过微软的 Frontier 计划率先向部分用户开放。微软将 Researcher 定位为 Microsoft 365 Copilot 中的核心研究型 AI 代理,随着多模型能力的加入,企业在市场调研、行业分析、内部报告撰写等场景中的自动化与精度都有望进一步提升。









