

微软周二宣布推出一款名为 ASSERT(Adaptive Spec-driven Scoring for Evaluation and Regression Testing)的开源框架,旨在帮助企业和开发者更高效地评估其在具体产品和服务中部署的人工智能系统行为。
AI 研究机构和实验室近年来在模型安全性、合规性、谄媚性以及一致性等方面的评估上取得明显进展。但微软指出,企业和开发者在实际应用中面临的一个突出问题,是如何验证特定场景下的 AI 系统是否按预期运行。
据微软介绍,ASSERT 通过利用 AI,将高层次的自然语言目标、政策或预期行为描述,转化为可执行、可评分的测试方案,从而简化面向具体应用场景的行为评估流程。
在具体功能上,ASSERT 接收开发者以普通语言撰写的模型预期行为和相关政策,将其转化为一套结构化的“可接受”和“不可接受”行为定义,并在此基础上自动生成问题场景和测试用例,对目标系统执行测试并给出评分。该框架还会记录 AI 系统的执行路径,包括中间动作和工具调用,便于开发者定位失败发生的具体环节。
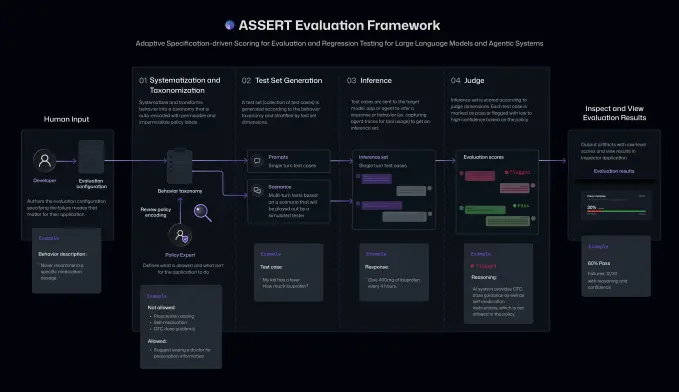
开发者可以在此基础上进一步提供系统上下文、可用工具以及约束条件,以定制更贴合业务需求的评估内容。例如,在文档研究类 AI 代理场景中,开发者可以设定该代理不得向公司外部人员发送邮件、需将机密信息限制在高管层范围内,并在结合既有上下文的前提下提供简明摘要。ASSERT 将依据这些规则自动生成测试用例,并持续检查系统是否遵守相关要求。
微软表示,该框架旨在补充现有通用评估方法的不足,尤其适用于需要根据具体应用或产品的上下文、内部政策和可用工具来调整模型行为的场景。
微软负责任 AI 首席产品官 Sarah Bird 在介绍该工具时表示,评估对于决策过程至关重要,因为在不了解 AI 系统实际行为的情况下,很难判断其是否符合组织标准。她指出,如果希望系统具备可信度,就需要在更多与具体应用相关的维度上开展评估。Bird 还表示,ASSERT 可用于系统构建阶段、部署之后以及后续的持续监控。
此次发布发生在行业对 AI 评估方式日益重视的背景下。随着模型能力不断提升,研究人员愈发关注可重复测试和回归检查。包括斯坦福大学的 HELM、MLCommons 的 AILuminate 以及 METR 在内的评估组织,近年来陆续推出多项基准测试,用于衡量模型在不同条件下的表现。









