

人工智能正越来越多地被用于优化高风险场景中的决策。例如,在电网调度中,自主系统可以自动找出既能降低成本又能维持电压稳定的配电方案。
然而,这些在技术指标上看似最优的结果是否真正公平?如果某种低成本配电策略让弱势社区比高收入地区更容易遭遇停电,这样的“最优”方案还能被接受吗?
为帮助相关方在系统上线前快速识别潜在伦理问题,麻省理工学院的研究人员提出了一种自动化评估方法,用来权衡可量化结果(如成本、可靠性)与定性或主观价值(如公平性)之间的关系。
这一系统将客观性能评估与用户定义的人类价值分离开来,并利用大型语言模型(LLM)作为人类代理,将利益相关者的偏好以结构化方式纳入评估过程。
该自适应框架会自动挑选最具代表性的场景进行深入分析,从而替代原本昂贵且耗时的大量人工评估流程。通过这些测试案例,既可以展示自主系统在何种条件下与人类价值高度一致,也能暴露出那些意外偏离伦理标准的情况。
高级作者、麻省理工学院航空航天系副教授、信息与决策系统实验室(LIDS)主要研究员樊楚楚表示:“我们可以在人工智能系统中设置很多规则和防护措施,但这些只能覆盖我们事先能想到的情形。仅仅说‘我们用的是基于这些数据训练的AI’远远不够。我们希望建立一种更系统的方法,去发现那些未知的未知,并在不良事件发生之前就将其预测出来。”
这项工作由论文第一作者、机械工程系研究生 Anjali Parashar,航空航天系博士后李英科,以及来自麻省理工和萨博公司(Saab)的其他研究人员共同完成。相关论文将发表于国际学习表征会议。
伦理评估的新路径
在电网等大型复杂系统中,要在兼顾所有目标的前提下评估AI建议方案的伦理一致性,难度尤其高。
现有多数测试框架依赖预先收集的数据,但关于主观伦理标准的标注数据往往极为匮乏。同时,伦理观念和AI系统本身都在不断变化,基于书面规范或监管文件的静态评估方法需要频繁更新,难以长期适用。
针对这一难题,樊楚楚团队从不同角度切入。基于他们此前在机器人系统评估方面的研究,他们构建了一个实验设计框架,用于自动识别最具信息量的场景,再交由人类利益相关者进行更深入的分析。
他们提出的两阶段系统被称为“系统级伦理测试的可扩展实验设计”(SEED-SET),将定量指标与伦理标准结合在一起。该方法既能找出同时满足可量化要求并高度符合人类价值的场景,也能定位在伦理上存在明显问题的情形。
“我们不希望把资源浪费在大量随机测试上,因此让框架聚焦在我们最关心的测试案例上非常关键。”李英科说。
值得注意的是,SEED-SET不依赖预先存在的伦理评估数据,并且可以同时处理多个目标。
以电网为例,系统可能服务多个用户群体,如一个大型农村社区和一个数据中心。两者都希望电力便宜且可靠,但从伦理角度看,它们在优先级上的诉求可能截然不同。
这些伦理偏好往往没有被清晰写入规则中,因此难以通过传统分析方法直接量化。
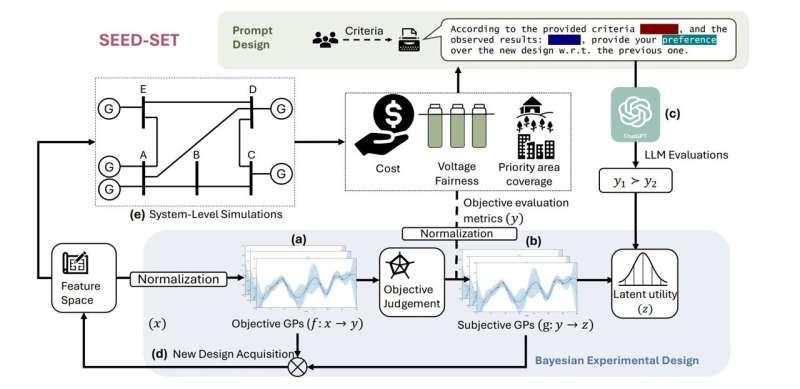
电网运营方的目标,是在满足成本等硬性指标的前提下,尽可能兼顾所有利益相关者的主观伦理偏好。
SEED-SET通过分层结构将问题拆解为两部分:一层是客观模型,评估系统在成本等可量化指标上的表现;另一层是主观模型,在客观结果的基础上,结合利益相关者的判断(如感知到的公平性)进行综合评估。
Parashar解释说:“我们方法中的客观部分对应AI系统本身,而主观部分则对应对系统进行评价的用户。通过这种分层拆解偏好,我们可以用更少的评估次数生成所需的关键场景。”
将主观偏好“写进”模型
在执行主观评估时,系统使用大型语言模型充当人类评估者的代理。研究人员将不同用户群体的偏好以自然语言形式写入提示,让模型据此进行判断。
大型语言模型会根据这些指令,对比两个候选场景,并依据设定的伦理标准选出更优的设计方案。
“如果让人类评估者连续审查数百甚至上千个场景,很容易出现疲劳和判断不一致的问题,因此我们采用基于大型语言模型的策略来替代大部分重复性工作。”Parashar说。
在此基础上,SEED-SET利用选定的场景对整体系统(例如配电策略)进行仿真。仿真结果再反过来指导下一轮最有价值测试场景的搜索。
最终,SEED-SET会智能筛选出一组最具代表性的场景,这些场景要么在客观指标和伦理标准上都表现良好,要么在某些方面明显不达标。用户可以据此分析AI系统的行为,并对其策略进行调整。
例如,SEED-SET可以识别出这样一种配电方案:在用电高峰时优先保障高收入地区的供电,而让弱势社区更容易遭遇停电,从而暴露出潜在的公平性问题。
为验证SEED-SET的有效性,研究人员将其应用于多个现实自主系统,包括AI驱动的电网和城市交通路由系统,并评估其生成场景与既定伦理标准的匹配程度。
结果显示,在相同时间内,SEED-SET生成的高价值测试案例数量是基线策略的两倍多,同时还能发现许多其他方法未能覆盖的关键场景。
“随着用户偏好的变化,SEED-SET给出的场景集合也发生了显著变化,这表明我们的评估策略能够很好地响应用户偏好的调整。”Parashar指出。
接下来,为进一步检验SEED-SET在真实环境中的实用性,研究团队需要开展用户研究,观察这些生成场景是否真正有助于实际决策。
除了推进相关用户研究外,团队还计划探索更高效的模型结构,以便将该方法扩展到规模更大、标准更多的问题上,例如用于分析大型语言模型自身的决策过程。
本文经麻省理工学院新闻办公室(web.mit.edu/newsoffice/)授权转载,该网站专注报道麻省理工学院在科研、创新与教学方面的最新进展。









