

楽天集团于2026年3月17日宣布,正式开始提供面向日语优化的大规模语言模型「Rakuten AI 3.0」。该模型是在经济产业省与新能源・产业技术综合开发机构(NEDO)主导的生成式AI开发项目「GENIAC」框架下开发完成,参数规模约为7000亿,被定位为日本国内规模最大的日语特化LLM之一。
国内领先规模的日语LLM,在多项基准测试中表现优异
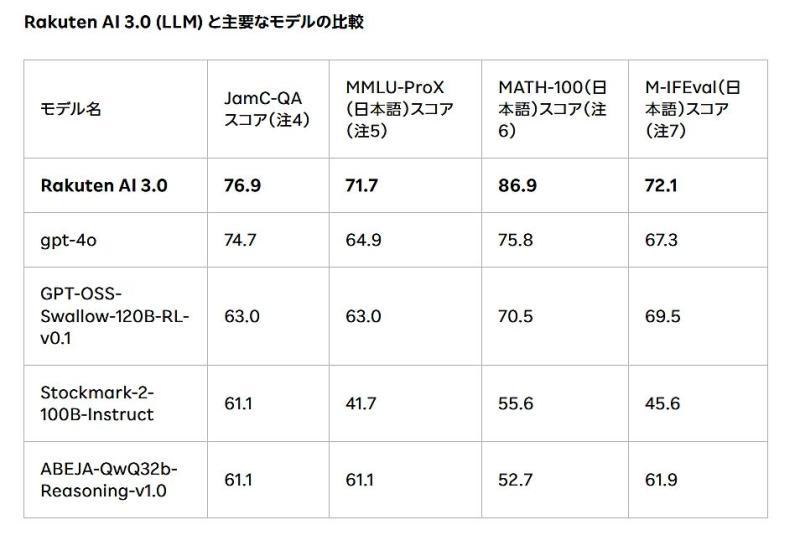
「Rakuten AI 3.0」是在2025年12月首次发布版本的基础上,经过进一步微调与改良后推出的升级版。根据楽天公布的信息,该模型在多项日语基准测试中取得了较高分数,评估维度包括:
- 与日本文化与历史相关的知识理解
- 研究生水准的推理与问题解决能力
- 竞赛级数学题目的解题能力
- 对复杂指令的理解与执行能力
在这些指标上,「Rakuten AI 3.0」与主要现有模型进行了对比测试,结果显示其在日语任务上的综合性能处于领先水平。
采用MoE架构的日语特化模型,覆盖多种企业级应用场景
「Rakuten AI 3.0」采用 Mixture of Experts(MoE)架构,专门针对日语场景进行优化。模型以开源社区现有模型为基础,结合楽天自有的双语数据与相关技术进行训练与改良,在性能与效率之间取得平衡。
该模型可用于多种任务,包括但不限于:

- 自然语言生成(如对话、文章撰写等)
- 代码生成与程序辅助开发
- 文档解析与信息抽取
与此前的版本相比,「Rakuten AI 3.0」在处理复杂任务时的准确性和稳定性都有明显提升,更适合在企业级业务系统和大规模应用中落地使用。
以 Apache 2.0 协议免费开放,面向企业与开发者
楽天将「Rakuten AI 3.0」作为开放模型提供,采用 Apache 2.0 许可证,用户可通过楽天的官方代码仓库免费下载与使用。该授权方式允许企业和开发者在遵守许可证条款的前提下,将模型用于商业或非商业用途,并进行二次开发与集成。
楽天集团 Chief AI & Data Office(r CAIDO)负责人ティン・ツァイ(Tin Tsai)表示,楽天正致力于打造高质量且具成本优势的大规模语言模型,并希望通过开源共享的方式,加速日本国内AI技术与应用的发展,推动更活跃的开发者社区生态形成。
GENIAC 项目支持下开发,充分利用计算资源支援
楽天在2025年7月入选了GENIAC项目第三期,得以获得项目提供的部分计算资源支持。「Rakuten AI 3.0」的训练过程正是基于这一支援完成。
作为集团整体AI战略的一部分,楽天提出了“AI-nization”计划,旨在在全公司范围内推动AI技术的应用与普及。通过公开「Rakuten AI 3.0」,楽天希望进一步促进日本国内AI应用开发的活跃度,并带动开源社区与产业界在生成式AI领域的协同发展。









