
人工智能(AI)系统大致可以分为三类:推理机器、学习机器和发现机器。圣路易斯华盛顿大学的研究人员正瞄准其中最罕见、也最具挑战性的“发现机器”。一项新研究提出了一种更优的构建路径,由该校麦克凯尔维工程学院克利福德·W·墨菲教授、研究副院长 Shantanu Chakrabartty 领衔完成。
这项成果已发表在《自然通讯》(Nature Communications)上,延续了团队此前关于混合系统架构的工作:一方面采用模拟人类神经生物学功能的“类脑”架构,另一方面引入利用量子力学原理寻找复杂问题最优解的系统。
Chakrabartty 表示,研究结果显示,这类机器不仅能持续、稳定地给出当前最先进水平的解答,而且在求解时间上也具备竞争力。
要理解新系统的思路,可以回到那三种不同类型的机器:
-
推理机器 是最常见、也最为人熟悉的一类,例如 ChatGPT 就可以视作推理机器。如果让大型语言模型(LLM)解魔方,它依靠事先训练好的步骤,在几秒内就能给出详细指导。
-
学习机器 则在没有预先给定步骤的情况下,从数据中“学会”如何解题。如果没人告诉机器解魔方的具体方法,而是让它自己探索所有可能的解法,就需要学习机器来完成。但随着问题复杂度提升,计算量、能耗和时间成本都会急剧增加。计算机与系统工程领域在构建这类机器方面也在不断进步。
-
发现机器 是最难实现的一类。它不仅要能找到某个难题的所有可能解,还要在数万亿个因素中筛选出最快、最优的那一个。这类任务需要充分利用随机性和噪声的力量。
在这项新研究中,Chakrabartty 基本给出了一套构建具备这种能力的 AI 机器的方案。他形容,这些机器被设计成可以“在干草堆里找到针”,而且能保证最终找到。
团队提出的“发现机器”框架本质上是一种混合系统:由类脑启发的自动编码器,再加上 Fowler–Nordheim 退火——一种源自量子力学的工具。Chakrabartty 认为:“这两个组成部分都是必需的,而且足够通用,可以应用于任何复杂问题。”
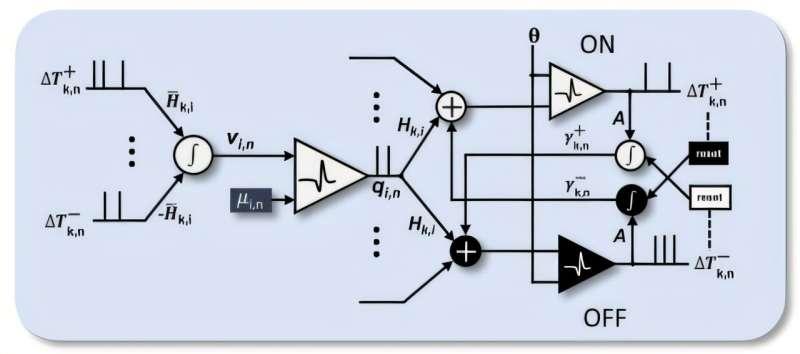
自动编码器是一种对海量数据流进行压缩的技术。通过压缩数据,机器可以进行模式预测,并不断重复压缩与预测的过程,直到预测足够准确。
Fowler–Nordheim 退火则是一种引入噪声和随机性的方式,使机器能够“隧穿”式地跳过局部极值,直接逼近全局最优解。这一点是研究人员相较传统计算方法获得最大优势的关键所在。
新型计算芯片已经可以支持模拟退火,这是一种利用量子力学原理进行量子计算的方式,能够更直接地引导研究人员接近“灵光一现”的解答时刻。借助他们构建的混合系统,团队可以对“发现机器”进行调节,以获得所需结果。
全球合作推动混合系统落地
这项研究依托神经形态工程研究所,并通过科罗拉多州特柳赖德神经形态 AI 研讨会、印度班加罗尔神经形态工程研讨会等年度头脑风暴活动,与全球多家机构合作完成。合著者来自印度科学研究院、德国海德堡大学、约翰霍普金斯大学以及加州大学圣克鲁兹分校。
Chakrabartty 的博士生 Faiek Ahsan 是论文第一作者,主要研究“发现”过程的突触起源机制。
多年来,团队一直尝试用标准测试问题——伊辛模型,来检验更高阶的挑战。即便是现有的神经网络,也很难高效解决伊辛模型。因此,他们提出在下一代 AI 模型中引入“轻度”的量子力学参与,以增强求解能力,而这也带来了额外的好处。
新提出的架构在高阶伊辛模型上的收敛性保证,与以往方法有所不同。这意味着无论机器是花六个月还是一年时间去寻找答案,最终都能给出一个解。在某些超级计算机的应用中,如果研究人员一开始给出的提示不够准确,可能白白等待一年却得不到有用结果。
Chakrabartty 打了一个比喻:这让他想到《银河系漫游指南》中的超级计算机“深思”,被问及“生命、宇宙以及一切的答案是什么?”结果花了几百万年才给出“42”这个答案,让创造者大失所望。而他们设想的“发现机器”不会出现这种情况。
“这种机器能给你一个保证,”他说,“六个月之后,一定会有一个有用的结果出现。”










