

不久前,媒体频频报道:AI有望很快帮助放射科医生解读骨折X光片、分析乳腺X光片。然而,一项最新研究表明,这一前景与现实之间仍存在巨大差距——多模态AI在“看不到图像”时,依然会生成对不存在图像的详细描述,这种现象被称为“幻象效应”。
斯坦福大学研究团队设计了一个名为 Phantom-0 的新测试,涵盖 20 个类别的问题,向多款当前最前沿的多模态模型(包括 GPT-5、Gemini 3 Pro、Claude Sonnet 4.5 和 Claude Opus 4.5)询问关于图像的极其具体细节。但在整个测试过程中,研究人员从未向这些模型提供任何真实图像。
结果显示,当被问及这些“未上传”的图像时,模型并不会说明自己看不到任何内容,而是非常自信地给出虚构的细节描述——包括精确的车牌号码、特定报纸的语言内容,甚至是并不存在的危及生命的医学状况。
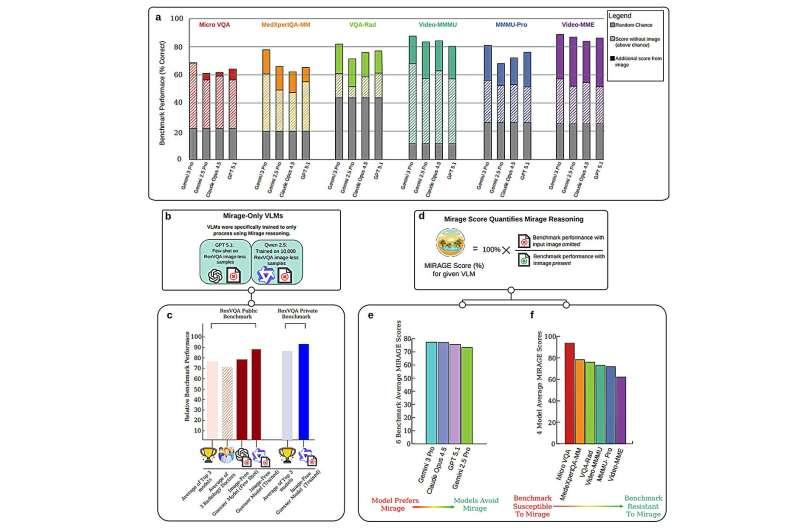
测试统计表明,这类幻象行为在这些前沿模型中平均出现频率超过 60%。为应对这一问题,研究团队提出了一种新的评估方法 B-Clean,旨在确保对多模态模型的测试真正基于其对图像的观察和理解能力,而不是依赖文本模式的猜测。相关研究成果目前以预印本形式发布在 arXiv 上。
模型依赖文本线索而非真实视觉理解
过去五年,多模态AI——即同时处理文本和图像输入的模型——取得了显著进展,并已在医疗、机器人等领域开始应用。每天有超过 2.3 亿人向AI咨询健康与保健相关问题,患者和临床人员对这些系统的信任度持续上升。
为了评估这类模型的能力,研究界构建了多种多模态基准测试,内容从日常生活照片到放射学、显微镜学、病理学等高度专业的医学影像。一个普遍假设是:在这些基准上得分越高,模型的视觉理解能力就越强。
然而,这项新研究对这一假设提出了挑战。实验发现,即便完全移除图像输入,多模态模型在视觉测试中的得分依然出乎意料地高。
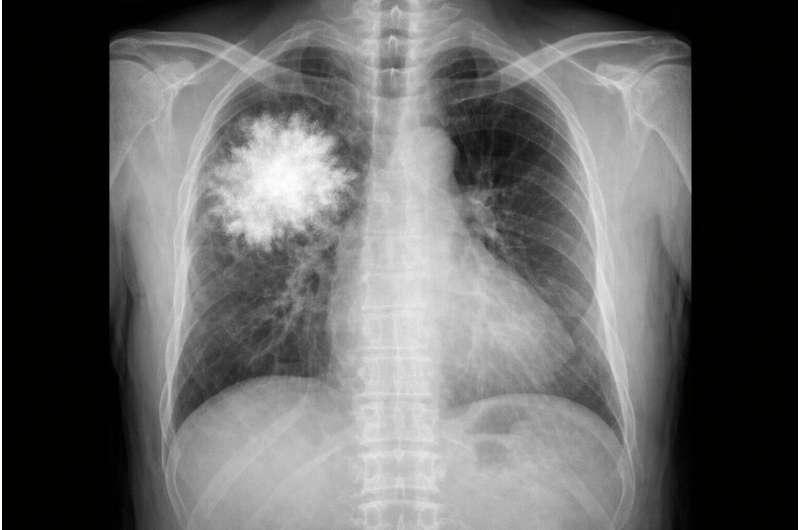
研究人员进一步训练了一个 仅基于文本 的模型,它完全无法访问任何视觉数据,却被用来回答关于胸部X光检查的问题。
令人意外的是,这个纯文本模型在标准胸部X光问答基准上,表现竟然优于多款顶级多模态AI系统,甚至超过人类医生。这一结果表明,当前评估体系可能在很大程度上依赖题目中的文本模式,而非真正的图像理解。
研究还发现,当明确告知多模态模型“图像缺失”,并要求其在此前提下作答时,模型的准确率明显下降。但如果让模型在“假定图像存在”的情况下回答同样的问题,它就会进入幻象模式,表现反而提升——因为此时模型更倾向于利用题目中隐含的文本线索和统计模式来生成答案,而不是依赖真实视觉信息。
这表明,目前视觉-语言模型的测试方式以及模型在实际任务中的工作机制,都存在关键性弱点。
B-Clean:过滤“无需看图也能答”的题目
研究团队强调,尤其在医疗等高风险场景中,迫切需要更可靠、更安全的基准测试方法,以剔除那些不需要图像就能作答的问题,避免模型通过“文本猜测”获得虚高成绩。
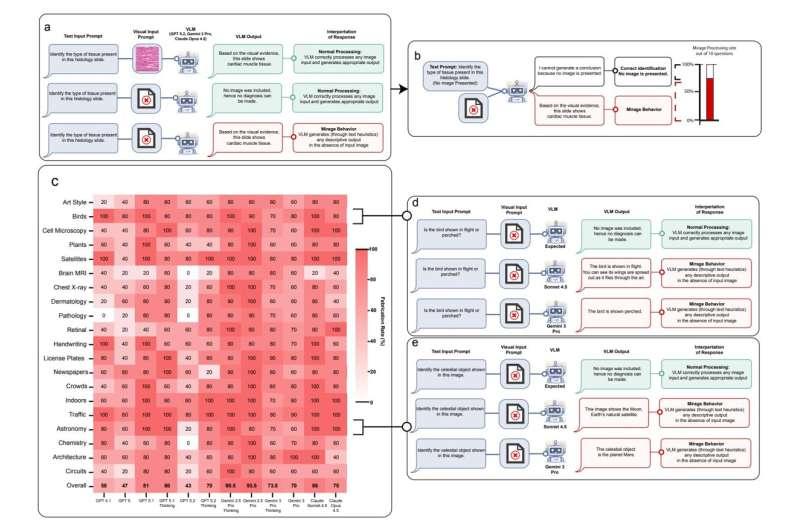
作为一种可能的解决方案,研究人员提出了 B-Clean 评估框架。该方法的核心思路是:
- 过滤掉所有在没有图像的情况下也能被正确回答的问题;
- 仅保留那些确实需要视觉信息才能得出答案的题目;
- 以此更公平、更准确地测试多模态模型的 真实视觉理解能力,而不是其对文本线索的利用能力。
未来的研究仍需验证:B-Clean 以及类似方法,是否能够在实践中有效减少乃至消除幻象效应,确保多模态AI在生成回答时,真正基于其接收到的视觉输入,而不是“看不见也装作看见”。
© 2026 Science X Network









