

向同一个人工智能模型用两种不同语言提出相同的政治问题,得到的回答可能截然不同。《自然》杂志近日发表的一项研究指出,一个关键原因在于:政府通过塑造本国的在线媒体环境,间接影响大型语言模型(LLMs)在训练阶段接触到的文本,从而改变模型在政治议题上的表现。
一支来自俄勒冈大学、普渡大学、加州大学圣地亚哥分校、纽约大学和普林斯顿大学的跨校团队发现,国家对媒体的控制,会在人工智能模型的行为中留下可检测的“制度印记”。
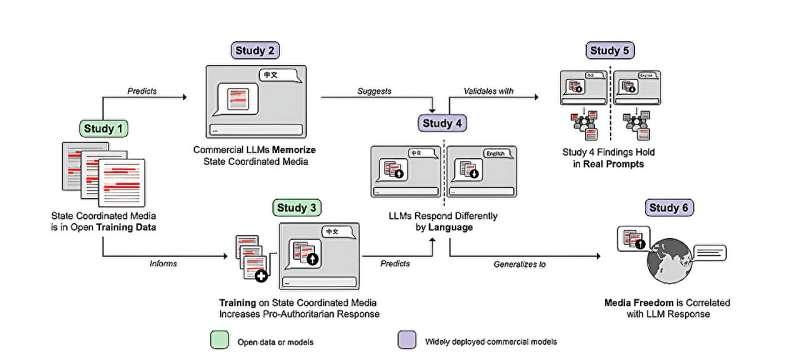
研究团队综合了对37个国家本地语言的大型语言模型评估结果,并以中国为案例展开深入分析。通过六项相互配合的研究,他们从在线媒体出发,一路追踪到训练数据,再到模型输出行为,结合了对开放训练数据的量化分析、小型模型的再训练实验、人类主观评估,以及对商业聊天机器人的真实环境测试。
俄勒冈大学社会学助理教授、论文共同第一作者汉娜·韦特指出,人们往往假定人工智能是以某种“中立”的方式从互联网学习,但现实并非如此。模型学习的是一个已经被各类机构和权力结构深度塑造的信息环境,而这种环境会在模型的输出中留下可测量的痕迹。研究团队将这一现象概括为“制度影响”。
国家媒体如何进入训练数据
纽约大学“社会媒体、人工智能与政治中心”联合主任、论文共同作者约书亚·塔克表示,公众讨论通常集中在“人工智能能生成什么内容”,而这项研究则把视角前移到“上游”:在人工智能系统影响政治之前,政治已经通过信息环境影响了人工智能。
为了追踪这种制度影响如何在训练过程中体现,作者首先证明:国家协调媒体内容在真实训练数据中出现频率很高。研究人员将两类中国国家协调媒体来源,与一个基于 Common Crawl 的主流开源多语言训练数据集进行比对,发现有超过 310 万份中文文档与这些媒体内容存在大量措辞重叠,占该数据集中中文子集的约 1.64%。
这一比例是中文维基百科文档占比的 40 多倍,而维基百科是常见的训练数据来源之一。在涉及中国政治领导人或政治机构的文档中,这一比例更是升至 23%。
值得注意的是,只有约 12% 的匹配文档来自已知的政府或新闻网站域名,这表明这些材料在进入人工智能训练语料库之前,已经通过各类网站和平台在网络上广泛扩散。
研究人员还发现,商业模型会记住与这些国家协调内容相关的独特短语,说明这些文本在训练过程中被多次呈现和学习。
普林斯顿大学社会学副教授、论文通讯作者布兰登·M·斯图尔特指出,国家协调内容并不只停留在官方媒体上,而是通过报纸、应用程序、转发和普通网页不断被复制和再传播,逐渐被“嵌入”到更广泛的信息环境中。一旦这些内容进入训练数据,模型就可能将其“洗白”为看似中立、客观的知识性输出。
小型模型再训练实验
接下来,团队检验这些国家协调内容是否真的会改变模型行为。
由于训练大型商业模型需要数月时间和巨额算力成本,研究人员转而在一个小型开源模型上进行实验,在其训练数据中有针对性地加入额外文档。
结果相当明确:在训练数据中加入脚本化新闻后,模型在相关政治问题上的回答更倾向于给出有利于特定立场的表述,相比未修改的模型,这种“更有利回答”的概率接近 80%。即便与其他非脚本化的中文媒体内容相比,尤其是与仅添加一般中文网络文本的情况相比,这一趋势依然显著。
普渡大学政治学助理教授、论文共同第一作者埃迪·杨解释说,当仅通过对训练数据做出小幅调整,就能在相同政治问题上系统性地改变模型回答,这表明这些额外文档确实在塑造模型行为方面发挥了实质作用。
语言差异暴露政治偏向
研究团队进一步推断,如果一个国家对预训练数据的影响足够强,那么这种影响应当在该国主要语言中表现得最为突出。以中国为例,关于中国政府的提问如果使用中文,模型的回答应比使用英文时更倾向于支持政府。
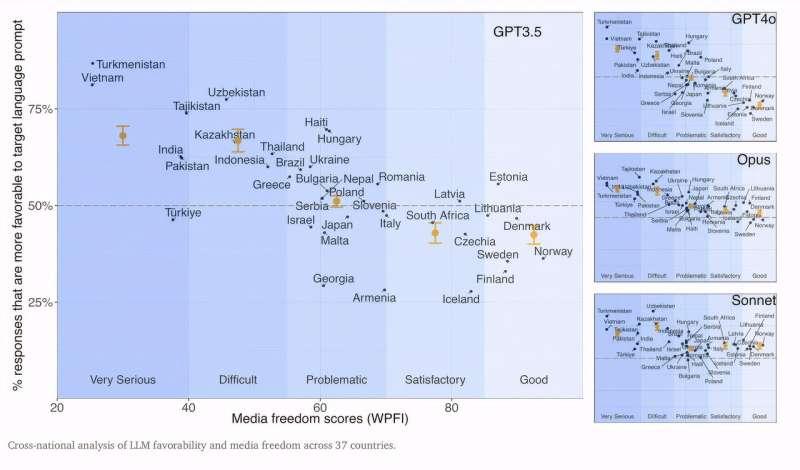
在无法访问模型内部参数的前提下,研究人员采用跨语言对比的方式来审视商业模型。他们让模型用不同语言回答关于中国的政治问题,再由人类评分者进行评估。结果显示,在涉及中国的政治问题上,人类评分者认为中文提示下的回答有 75.3% 的概率更有利于中国政府。
而对于与中国无关的政治问题,这种语言差异则接近随机水平。语言之间的系统性差异,为研究者提供了一个观察封闭商业系统的罕见窗口。后续基于真实用户提问、并覆盖更多商业模型的研究同样发现:在涉及中国领导人和政治机构的问题上,中文提问往往比英文提问得到更有利的回答。
更广泛的跨国模式
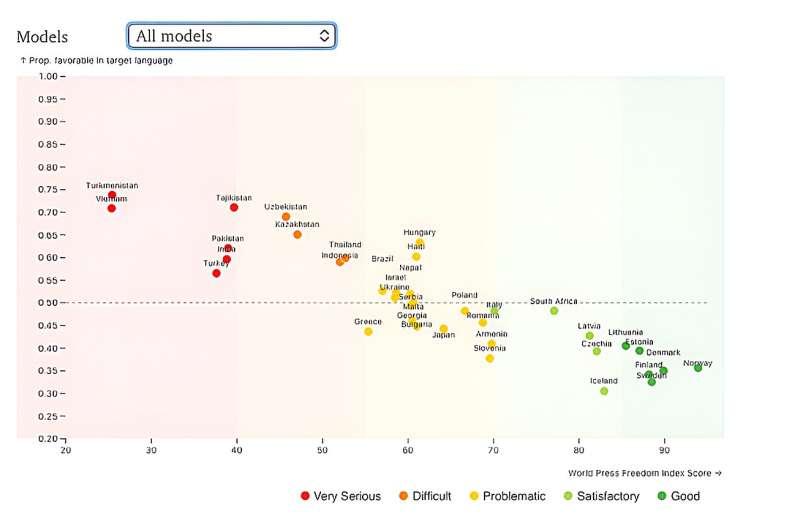
研究人员还证明,这种现象并非中国独有。在对 37 个国家进行的跨国分析中,他们聚焦于这些国家在本国使用最广泛的国家语言。结果发现,在媒体控制更强的国家,模型在该国语言下对本国政府和机构的态度更为正面,而在英文回答中则不呈现同样的模式。
作者强调,这一结果是相关性而非因果性证明,但与在中国案例研究中识别出的机制高度一致。
加州大学圣地亚哥分校政治学教授、论文共同作者玛格丽特·E·罗伯茨指出,这并不意味着人工智能公司主动迎合这些政府,也不意味着政府是专门为了影响聊天机器人而控制媒体系统。更合理的理解是:国家塑造信息环境,信息环境塑造训练数据,而训练数据又塑造模型输出。展望未来,这一发现意味着,大型语言模型可能为强势行为体提供新的激励,使其更有动力去战略性地规划和操控在线文本传播。
权力与透明度的启示
作者提醒,目前没有任何单一测试可以完整还原商业模型的训练过程,因为相关细节大多未公开。因此,论文采用了多种互补方法:开放源训练数据分析、对商业系统的记忆测试、小型模型再训练实验、人类主观评估、真实用户审计以及跨国比较研究,共同勾勒出政治权力进入人工智能系统的一条重要路径。
在项目网站上,研究团队还展示了使用最新发布模型复现实验结果的情况。
研究人员同时强调,除了国家之外,其他强大机构同样可能通过大规模在线文本来影响训练数据。纽约大学“社会媒体、人工智能与政治中心”研究副教授、论文共同作者所罗门·梅辛指出,训练数据是现代人工智能的根基。如果希望理解这些模型在多大程度上反映了强势群体的利益,就必须弄清训练数据的具体来源,而这首先需要在训练数据内容上实现更高程度的透明度。









