

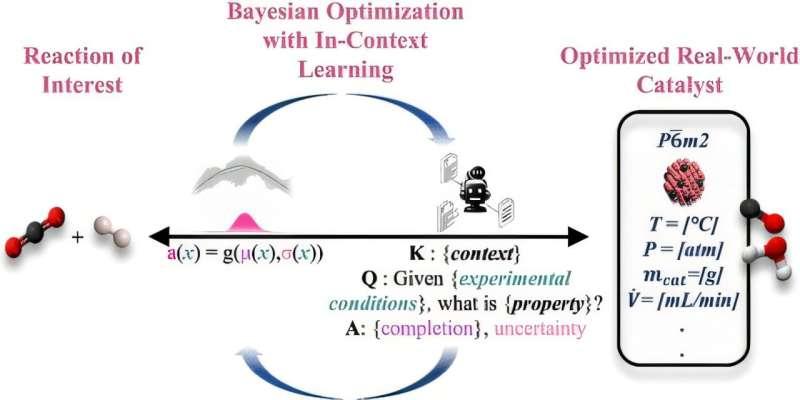
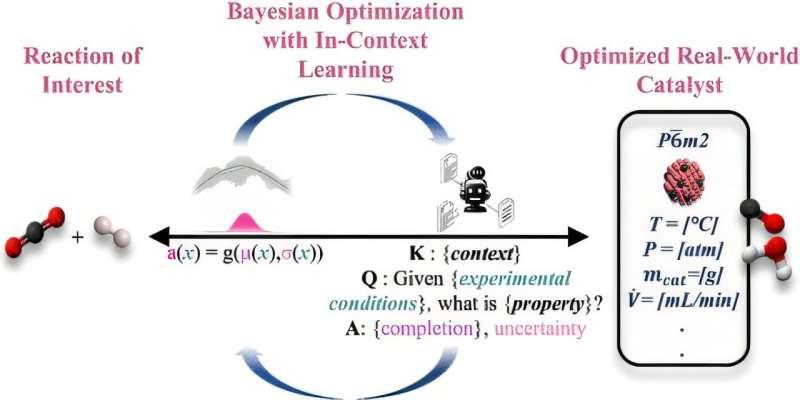
人工智能在材料研发中的应用正从“生成候选结构”走向“输出可执行实验流程”。罗切斯特大学研究人员近日在《ACS Central Science》发表研究,提出一种基于大型语言模型(LLM)的材料发现方法:研究人员可直接输入自然语言提示,系统据此给出制备目标材料的实验程序,并在实验结果回传后持续迭代,直至满足预期性能。
以自然语言驱动的材料发现工作流程
该研究由罗切斯特大学化学与可持续工程系副教授Marc Porosoff与访问副教授Andrew White(Edison Scientific联合创始人兼首席技术官)共同领导。团队表示,新流程结合了大型语言模型的预训练知识与材料发现中常用的统计方法,使研究人员能够更高效地在庞大的实验设计空间中筛选路径。
Porosoff在研究中将这一思路类比为“描述一杯咖啡”:既可以用味道、颜色、香气等属性描述,也可以用咖啡豆种类、研磨度、器具与水温等“配方”描述。两种描述指向同一结果,但后者更便于复现。团队将类似原则用于能源催化剂研发,通过语言化表示同时覆盖材料属性与制备步骤,从而让输出更贴近实验室可操作的流程。

与传统材料发现AI路径的差异
研究团队指出,传统材料发现的人工智能方法常采用贝叶斯优化来在复杂参数空间中寻找最优候选,但输出往往是关于材料结构的复杂数值数据,需要较强的专业背景才能转化为实验方案。相比之下,基于大型语言模型的方法可直接生成一套实验程序,便于研究人员理解、执行,并据实验结果验证预测。

该方法对三金属催化剂等复杂体系尤为适用。参与该方法开发的罗切斯特大学化学工程博士生Shane Michtavy表示,这一做法降低了贝叶斯优化的使用门槛;同时,使用处于“冻结状态”的预训练大型语言模型,使研究人员在更少数据条件下也能开展探索。
概念验证:十次实验筛选理想候选
论文展示了该方法在多项现场实验中的应用,包括使用低成本金属制备三金属催化剂,并用于识别可将二氧化碳与氢气转化为一氧化碳和水的催化剂。Porosoff表示,相关实验组合的潜在空间约为36万个,但团队通过模型生成程序并将实验结果反馈给模型,仅用十次实验就找到了理想候选材料。
获ARPA-E近300万美元资助,聚焦二氧化碳制燃料
在概念验证基础上,美国能源部先进研究项目局能源(ARPA-E)宣布将提供近300万美元资金,支持该团队进一步开发从丰富原料生产燃料的催化剂,重点包括利用二氧化碳与氢气生产甲醇和乙醇。Porosoff将牵头多机构项目团队,成员包括罗切斯特大学、弗吉尼亚理工大学、斯坦福大学、西北大学、新加坡A*STAR可持续化学、能源与环境研究所(ISCE2),以及总部位于盐湖城的小型企业OxEon Energy。
Porosoff表示,当前从构思新催化剂到实验室测试再到反应器应用通常需要十年或更长时间;ARPA-E“高通量实验与高效建模加速学习化学催化应用测试(CATALCHEM-E)”项目旨在将周期缩短一个数量级至一年。团队计划先在二氧化碳制甲醇上展示工作流程,再扩展至乙醇等更高阶醇类,并最终推动模型商业化,供工业界用于开发合成燃料醇类催化剂。









