

TurboLynx:复杂关系数据分析提速 184 倍
浦项科技大学计算机科学与工程系及人工智能研究生院的韩旭新教授团队,与博士生李泰成、河在贤共同研发出一款名为 TurboLynx 的新型引擎,可在分析复杂、高度互联数据时,比现有系统快 184 倍。
该成果计划在 2026 年 8 月 31 日至 9 月 4 日于波士顿举行的 VLDB 大会上正式发布。
面向“解读关系”的核心技术
支撑 TurboLynx 的底层技术,与当前多种关键应用场景密切相关:
- 流媒体平台根据用户偏好进行内容推荐;
- 金融机构识别可疑交易行为;
- 生成式人工智能理解人与概念之间的关联。
这些应用的共同点在于,需要快速、准确地“解读关系”。
图数据与现实世界的复杂连接
用于表示复杂连接网络的数据——例如人与人之间的社交关系、商品与交易之间的联系、词语之间的语义关联——被称为 图数据。
图数据库技术 专门用来存储和分析这类高度互联的信息网络,其结构类似一张多维度的“蜘蛛网”,节点与边之间关系密集而多样。
“无模式”数据带来的性能难题
现实世界中的企业数据往往具有高度多样性和不规则性:
- 数据结构会频繁变化;
- 新属性可以随时添加;
- 事先不强制定义固定模式,即所谓的 “无模式”数据格式。
这种灵活性虽然方便业务快速演进,却让现有系统在执行聚合、统计分析等任务时,性能常常大幅下降。
可以将其类比为:
一家餐厅中,每位顾客的点单格式都不一样,工作人员必须逐条阅读、理解后才能统计当天的销售额,效率极低。
从存储到查询的系统级重构
为解决上述问题,研究团队对系统从底层存储到查询处理、再到查询优化进行了整体性重设计。核心思路是:
将相似数据自动归组,并成批高效处理。
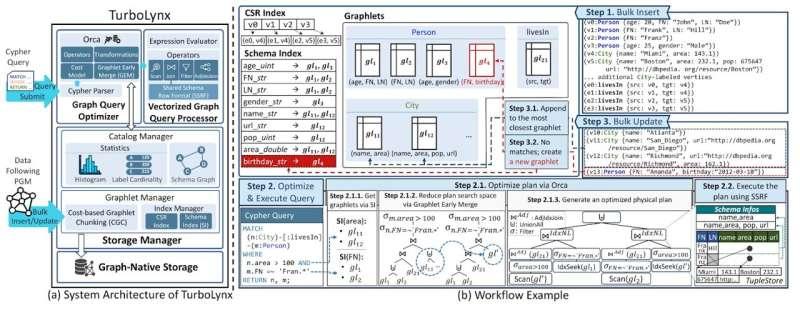
在 TurboLynx 中:
- 系统会自动识别并将具有相似特征的数据划分为若干组;
- 每个数据组采用针对分析任务优化的 列式存储格式;
- 读取数据时无需反复解析复杂的数据结构;
- 同时显著减少不必要的内存占用。
此外,TurboLynx 还针对复杂、多步骤图遍历过程中产生的大量中间结果进行了优化,抑制了中间数据的“膨胀”,使分析查询执行更加高效。
基准测试中的性能验证
通过国际公认的标准基准测试,TurboLynx 的性能优势得到了量化验证:
- 相比现有图数据库系统,TurboLynx 在分析任务上最高 快约 184 倍;
- 相比传统关系数据库系统,性能最高可 提升至 41 倍。
在基于大规模维基百科知识图谱的数据集测试中,TurboLynx 的表现:
- 相比表现最好的竞争系统,快约 19 倍;
- 展示出在真实工业级应用场景中的显著潜力。
面向生成式 AI 与行业应用的前景
随着复杂关系数据在多个领域迅速扩张,包括:
- 生成式人工智能;
- 推荐系统;
- 金融安全与风控;
- 生物医学数据分析等,
对高效图数据分析的需求愈发迫切。TurboLynx 有望为这些场景提供 近实时分析能力 的基础支撑。
研究团队将其比喻为:
就像电影中的侦探可以在瞬间梳理庞大的犯罪网络,企业也能更快速地洞察并利用海量数据中的隐含关系。
韩旭新教授表示,希望 TurboLynx 能帮助企业在实际分析和服务中,更广泛地挖掘和利用复杂图数据的价值。他补充称,团队计划继续推进研究,使系统进一步:
- 支持实时事务处理;
- 作为人工智能代理的长期记忆存储层。
开源与易用性:Cypher 与自然语言查询
TurboLynx 支持业界广泛使用的图查询语言 Cypher,这意味着:
- 已熟悉图数据库的工程师可以快速上手;
- 普通用户也可通过自然语言查询与系统交互,由系统将自然语言转换为 Cypher 查询。
目前,TurboLynx 已以 开源项目 形式发布,相关技术资料与访问方式可通过项目网站获取,方便研究机构与企业进行试用与二次开发。









