

上月,有研究围绕初创公司 Mercor 推出的新基准展开,评估各大实验室开发的 AI 代理在法律和企业分析等专业任务上的表现。当时,各模型在该基准上的得分均未超过 25%,由此得出的结论是,至少在当时,法律从业者尚无需担忧被此类系统取代。
本周发布的最新结果显示,相关情况在短时间内出现明显变化。Anthropic 推出的新模型 Opus 4.6 在 Mercor 的代理式 AI 排行榜上取得领先:在一次性测试中得分接近 30%,在允许多次尝试解决问题的设定下,平均得分达到 45%。
据介绍,此次发布包含多项面向代理场景的新功能,其中包括“代理群”等设计,被认为可能有助于处理多步骤问题。这些功能被视为 Opus 4.6 在复杂任务上得分提升的潜在原因之一。
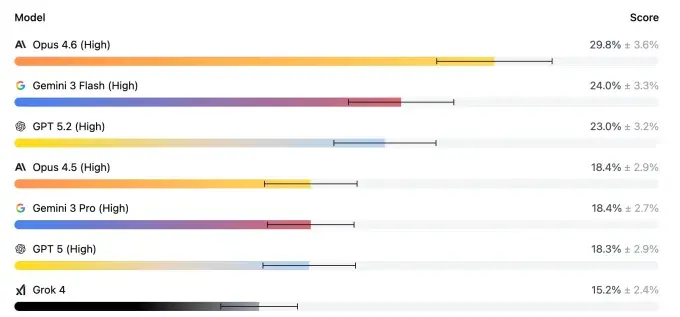
与此前最先进水平相比,Opus 4.6 的成绩被形容为“巨大飞跃”。Mercor 首席执行官 Brendan Foody 表示,从几个月前的 18.4% 提升至 29.8%,“简直疯狂”。他认为,这一变化显示基础模型能力在近期并未出现放缓迹象。
尽管如此,当前约 30% 的一次性测试得分与 100% 之间仍存在明显差距。相关表述指出,这意味着律师等专业人士在短期内并不会被此类系统直接取代,但与上月相比,其对自身岗位安全性的信心可能已明显减弱。
发表评论
登录后才可评论。
去登录









