

Anthropic高管:AI下一阶段将从被动响应走向主动预测
Anthropic旗下Claude Code和Cowork产品负责人Cat Wu表示,随着模型能力持续提升,AI产品正从同步交互迈向主动理解和自动化执行,未来有望在用户意识到需求之前进行响应。


Anthropic 面向大众推出最强「Mythos 级」AI:Claude Fable 5,高风险请求自动切换至 Opus 4.8
Anthropic 发布新一代顶级模型 Claude Fable 5,将原本仅限特定伙伴使用的 Mythos 级能力开放给一般用户,并通过内置保护机制,在网络安全、生命科学等高风险领域自动回退到 Claude Opus 4.8,以降低被恶意利用的风险。

本地化大模型兴起:开发者推动人工智能走向多语言与多文化
在英语与中文长期占据主导的人工智能领域,一批来自全球各地的开发者正尝试构建面向本地语言和文化的大模型,从埃及到瑞士、拉美和东南亚,草根项目与机构合作并行推进,试图改变现有技术版图中的语言失衡。
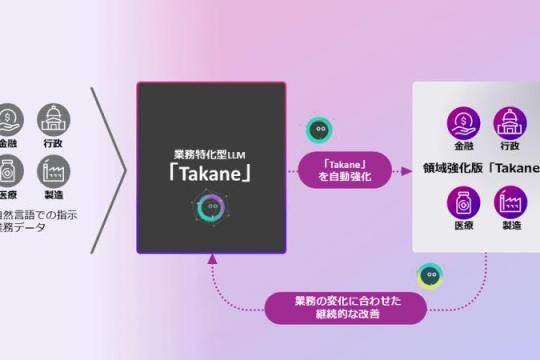
富士通开发“自我进化多AI代理技术”,自动强化 Takane,平均精度提升28个百分点
富士通发布可让多个AI代理协同执行业务并在实际运用中持续学习的“自我进化多AI代理技术”,用于自动强化行业特化大模型 Takane,在多领域实现平均28个百分点的精度提升。
人工智能成本飙升:企业开始冷静审视投入回报
在“补贴智能”红利退去、算力与代币费用全面上扬的背景下,企业对大规模采用生成式AI的态度正从盲目追捧转向精打细算。

Anthropic正式发布 Claude Opus 4.8:强化编码与智能代理能力,价格与 4.7 持平
Anthropic 推出最新旗舰模型 Claude Opus 4.8,在复杂推理、代理型编码、长时长任务一致性以及“诚实性”(honesty)方面全面升级,同时保持与 Opus 4.7 相同的定价,并面向 Claude 各付费档位及多家云平台开放。
东京都启动行政专用国产AI模型建设:面向高校公开招募合作机构,最高投入1.1亿日元开展实证
东京都与GovTech东京启动行政特化型国产AI模型联合研究招募,计划与一所大学或研究机构签约,在2026年度最多投入1.1亿日元,用于构建能处理行政文书与法令、并可追溯判断依据的AI模型,并与都职员用生成AI平台「A1」联动,推动行政AI的实用化。

谷歌发布Gemini企业代理平台 聚焦IT与技术团队
谷歌在Google Cloud Next大会上推出Gemini企业代理平台,将目标用户明确锁定为企业IT和技术团队,并与现有的Gemini企业应用形成区分。
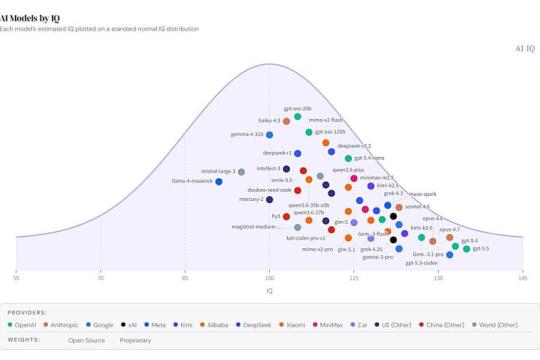
AI模型评估项目「AI IQ」上线:用“IQ”刻度比较 GPT-5.5、Claude Opus 4.7 等前沿模型
工程师兼创业者 Ryan Shea 推出 AI 模型评估项目「AI IQ」,尝试将多种公开基准测试结果统一映射到类似人类 IQ 的直观刻度上,并同时展示模型的推理能力、情绪智力(EQ)与使用成本。

从回合制对话到实时协同:前 OpenAI CTO 米拉·穆拉蒂团队发布「Interaction Models」
前 OpenAI CTO 米拉·穆拉蒂创立的 AI 初创公司 Thinking Machines Lab 发布实时协同 AI「Interaction Models」研究预览,试图突破传统回合制聊天模式,让人机可以像人与人一样同时说话、随时打断、根据画面变化即时响应。

HumanX大会聚焦代理型人工智能 Claude成场内高频话题
在旧金山举行的HumanX人工智能大会上,代理型AI应用成为讨论重点,多名与会者称更常使用Anthropic的Claude,而非ChatGPT。

Anthropic短暂暂停OpenClaw创始人Claude账户 引发第三方接入与定价争议
Anthropic在调整Claude订阅服务对第三方接口的支持和收费方式后一周,短暂暂停了OpenClaw创始人账户访问Claude,引发业界对第三方工具接入策略的关注。






