

Apple 的研究团队在 2026 年 3 月公布了一种全新的 3D 表达方式「LiTo」,能够同时表示物体的 3D 几何形状,以及随观察视角变化而改变的外观。借助这一表示,只需一张图片作为条件,就可以生成在不同视角下仍能保持真实反射、高光与光泽效果的 3D 对象。
LiTo 并不是传统意义上的 3D 重建模型,而是以「3D 潜在表示」为核心的方法:它将几何结构与视点依赖的外观统一编码在同一潜在空间中。相关论文已于 2026 年 3 月 11 日发布在 arXiv 上,并被国际学术会议 ICLR 2026 接收。
不只还原形状,还要还原“看起来的样子”
■ LiTo(左)能够在不同视角下稳定重现高光与反射,而传统方法(右)在视角变化时往往出现外观破绽

在以往的 3D 重建或图像到 3D 生成任务中,模型通常可以较好地恢复物体的几何形状,但要精确保留镜面反射、金属光泽等随视角变化的细节却非常困难。视角一旦改变,高光位置、反射强度等往往会出现不自然的跳变或失真。
LiTo 针对这一难题,将 RGB-D 图像视为「表面光场(surface light field)」的采样数据,并将其压缩为紧凑的潜在向量。通过这种方式,物体的形状信息与视点依赖的外观被一体化建模。
如上图所示,LiTo 能够让物体表面的高光位置随着视角变化自然移动,这意味着模型成功捕捉并重现了现实世界中“光照随视角变化”的物理现象。
这一能力不仅适用于简单几何体,在结构更复杂的物体上同样有效。
■ 在机器人示例中,LiTo(左)能保持姿态与外观的一致性,而传统方法(右)则容易出现朝向错误或结构扭曲
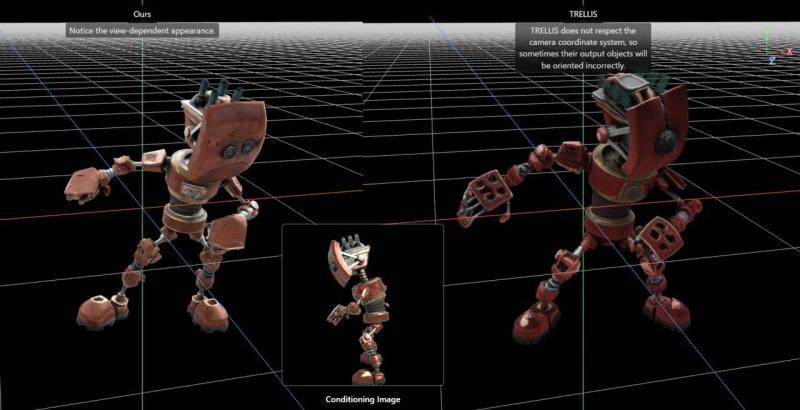
对于机器人这类具有多关节结构的对象,LiTo 能在保持与输入图像一致的前提下生成 3D 模型;而传统方法往往无法与相机坐标系保持一致,导致物体朝向混乱、肢体或结构出现破碎和错位。

从单张图片生成与光照和材质一致的 3D
在完成 3D 潜在表示的设计后,LiTo 进一步学习这一潜在空间的分布,从而构建出「以单张图像为条件的 3D 生成模型」。
利用该模型生成的 3D 对象,在外观上会与输入图像中的光照环境和材质特性保持一致。例如:
- 金属表面强烈而集中的高光
- 随视角变化而改变的反射强度(如 Fresnel 效应)
这些细节都能在生成的 3D 模型中被保留下来,使得物体在旋转或从不同角度观察时,依然呈现出符合物理直觉的视觉效果。
与既有方法相比,输入忠实度显著提升

在论文中,研究团队将 LiTo 与多种现有的 image-to-3D 方法进行了对比。结果显示:
- 在对输入图像的忠实度方面,LiTo 有明显提升
- 尤其是在高光、细小装饰等精细外观元素的还原上,LiTo 更接近真实物体(ground truth)
同时,LiTo 在提高输入一致性的前提下,并未明显牺牲整体视觉质量,生成结果在细节与整体观感之间取得了较好的平衡。
基于表面光场的 3D 潜在表示与生成框架
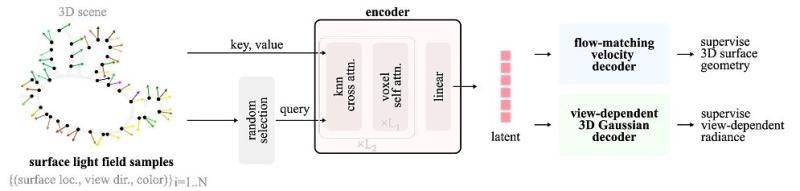
LiTo 的核心是基于表面光场构建的 3D 潜在表示。具体而言:
- 从 RGB-D 图像中获取表面光场采样
- 使用编码器将这些采样压缩到潜在空间
- 再通过两个解码器分别重建:
- 物体的几何结构
- 随视角变化的辐射亮度(即外观)
在此基础上,研究团队进一步对潜在表示的分布进行建模,从而实现「以单张图像为条件」的 3D 生成:输入一张图片,即可在潜在空间中采样并解码出与之匹配的 3D 对象。
ICLR 2026 收录的 Apple 研究成果
LiTo 由 Apple 机器学习研究团队于 2026 年 3 月正式公开,并在同月 11 日将论文提交至 arXiv。该工作已被国际顶级会议 ICLR 2026 接收。
在单张图像到 3D 生成这一长期难题上,LiTo 提出了一个关键方向:通过统一建模形状与外观,使得生成的 3D 对象在视角变化时不易出现破绽,能够更真实地还原现实世界中“看起来的样子”。









