

Google Cloud 于 2026 年 4 月 22 日(当地时间)在年度大会「Google Cloud Next」上宣布,将全面扩展其 AI 基础设施平台「AI Hypercomputer」。在自研芯片方面,推出第 8 代 AI 专用芯片「TPU 8t」与「TPU 8i」,分别面向训练与推理场景;在 GPU 生态方面,则引入基于 NVIDIA 下一代 GPU 平台的新实例。Google 一方面持续提升自家芯片能力,另一方面也加深与外部 GPU 生态的整合,意在整体强化云端 AI 算力供给。
第 8 代 TPU:训练与推理分离设计

本次发布的第 8 代 TPU 采用按用途区分的双型号设计:
- TPU 8t:面向大规模模型的预训练与再训练等高强度训练任务,重点优化吞吐量与可扩展性。在大规模部署形态下,可将数千颗芯片组合成一套系统,以显著加速大模型训练过程。
- TPU 8i:主要针对推理、强化学习以及各类 AI 代理(Agent)执行等运行阶段的工作负载。其设计更注重实时响应能力与持续推理场景下的内存结构和数据保留效率。
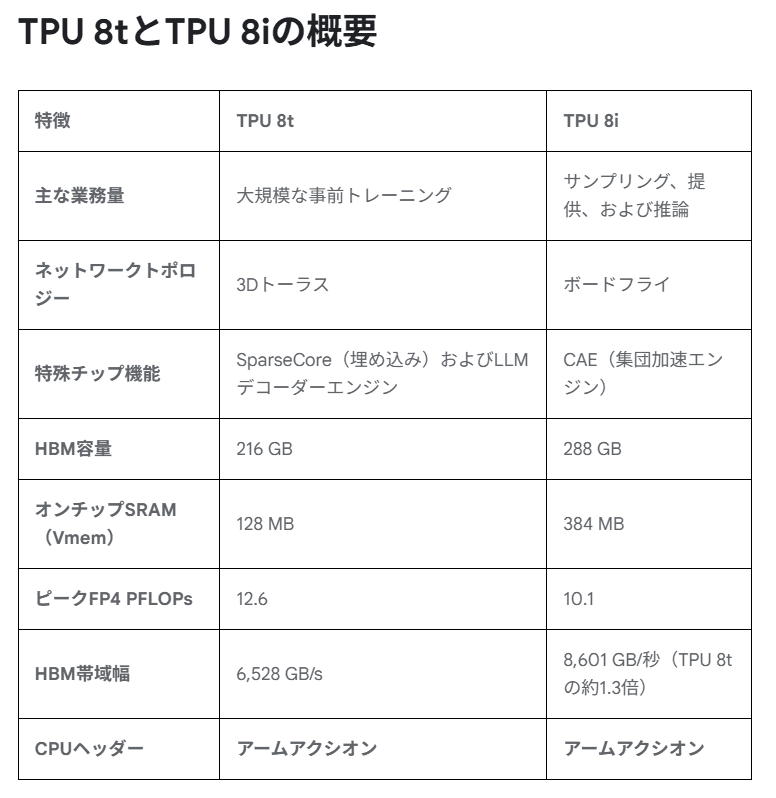
与以往尝试用同一硬件同时覆盖训练与推理不同,Google 此次明确将两类需求拆分,通过在架构层面分别优化训练与推理特性,来挖掘各自场景下的极致性能与效率。
推出采用 NVIDIA 下一代 GPU 的新云实例

在自研 TPU 之外,Google Cloud 也同步发布了基于 NVIDIA 下一代 GPU 架构的新型云实例。这类实例将以裸金属(Bare Metal)形态提供,面向超大规模 AI 工作负载,目标是在保证高性能的同时,进一步降低推理成本并提升能效表现。
NVIDIA 方面也借同一活动宣布将与 Google Cloud 深化合作,计划在云端进一步扩展 GPU 在「物理 AI」领域的应用,包括面向智能体(Agent)型 AI、机器人技术等场景的执行平台。双方将从模型开发、训练到部署与运行多个环节协同发力,共同强化 AI 基础设施能力。

AI Hypercomputer 向一体化 AI 基础平台演进
上述更新均被纳入 Google Cloud 的整体 AI 基础设施战略——「AI Hypercomputer」。这一平台不仅整合 TPU、GPU 等算力资源,还将网络与存储深度融合,面向云原生与大规模分布式处理进行系统级设计。
在本次扩展中,除了引入 TPU 8t/8i 和新 GPU 实例外,Google 还同步优化了专用网络与存储架构,使其与算力资源协同工作。重点不再只是单颗芯片的峰值性能,而是通过多种计算资源的组合与编排,提升整个系统层面的吞吐、延迟与可靠性。
面向 Agent 型 AI 与物理 AI 的基础设施
Google Cloud 指出,AI 的使用方式正在从一次性推理调用,转向能够持续感知、决策与行动的「Agent 型 AI」。在这类场景中,系统需要连续执行多步处理流程,因此不仅要求高推理性能,还需要整体系统具备更好的响应速度与资源利用效率。
同时,Google 也在加速布局与现实世界紧密耦合的「物理 AI」,例如机器人、工业仿真等应用。通过与 NVIDIA 的仿真平台及 AI 软件生态集成,Google Cloud 计划为制造、物流等行业提供更完善的云端 AI 基础设施,推动 AI 在各类产业场景中的落地与扩展。









