

Google Research 于 2026 年 3 月 24 日公布了一组面向大规模语言模型(LLM)和向量检索引擎的新型压缩技术。在最新论文《TurboQuant: Ultra-Efficient KV Cache Compression via Polarization and QJL》中,研究团队提出了一种专门用于压缩推理阶段键值(Key-Value, KV)缓存的技术方案——TurboQuant。
研究结果显示,TurboQuant 至少可以将 KV 缓存的内存占用缩减 6 倍,同时在长序列推理场景下,推理速度最高可提升约 8 倍,而整体精度几乎不受影响。
TurboQuant 通过高效压缩 LLM 的 KV 缓存,在显著降低内存占用的同时,大幅提升推理速度

KV 缓存:长上下文 LLM 的核心瓶颈
在文本生成过程中,LLM 需要保存历史 token 的中间表示,以便注意力机制(Attention)在后续步骤中进行高效计算。这部分被缓存下来的键和值向量,就被称为 KV 缓存。
随着模型上下文长度不断拉长到数十万 token 级别,KV 缓存会线性增长,逐渐成为 GPU 显存占用的主要来源,也是当前大模型推理扩展到超长上下文时的关键瓶颈。
为缓解这一问题,研究社区近年持续探索 KV 缓存量子化与压缩技术。不过,许多传统方法需要引入额外的缩放、偏置或其他辅助参数,导致压缩带来的收益被额外开销部分抵消,内存节省有限。
针对上述痛点,Google Research 提出了将多种新型压缩方法组合在一起的算法框架 TurboQuant,以在不牺牲精度的前提下,最大化 KV 缓存的压缩率。
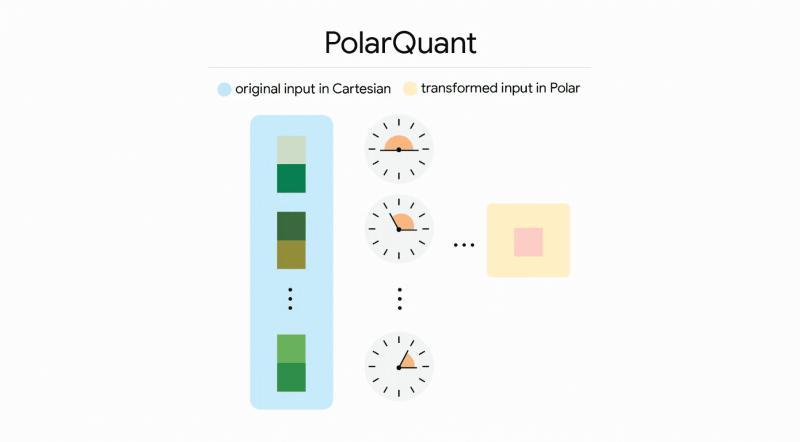
PolarQuant:用极坐标来量化向量
TurboQuant 的核心创新之一,是名为「PolarQuant」的量子化方法。
与传统在直角坐标系(x, y, ...)中直接量化向量不同,PolarQuant 首先将向量转换到极坐标系,用半径(模长)和角度来表示,再对这些量进行量子化。通过这种方式,可以在更少的比特数下,仍然较好地保留向量的几何结构信息。
更重要的是,PolarQuant 在设计上避免依赖额外的归一化或缩放参数,从而减少了量子化本身带来的内存开销,使得整体压缩效果更加显著。

■ PolarQuant 概念示意:先将向量转换为极坐标(半径与角度),再进行量子化,从而用更少的比特数表达原始向量信息
在大幅压缩 KV 缓存的同时保持精度
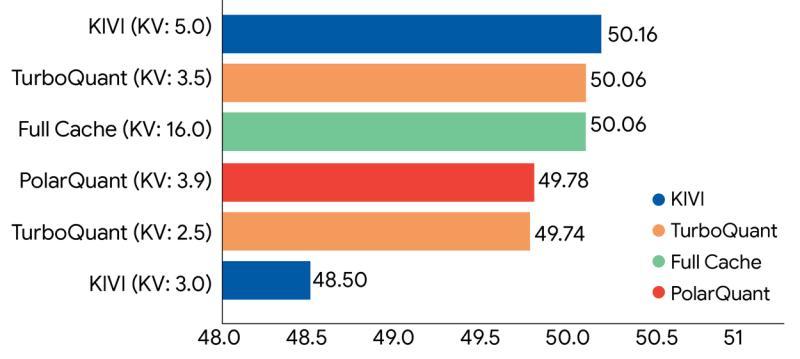
研究团队对多种 KV 缓存量子化方案进行了系统对比实验,将 TurboQuant 与传统方法(如 KIVI)以及未量子化的全精度 KV 缓存进行评估。
实验结果表明,即便在大幅降低 KV 缓存比特数的设置下,TurboQuant 的模型性能指标依然与全精度 KV 缓存几乎持平,明显优于多种现有量子化方案。这意味着在实际部署中,可以在不牺牲模型效果的前提下,显著压缩 KV 缓存。
■ 各类 KV 缓存量子化方法的精度对比:TurboQuant 在高压缩率下,依然能维持与全精度 KV 缓存近乎相同的性能
推理速度最高可提升约 8 倍
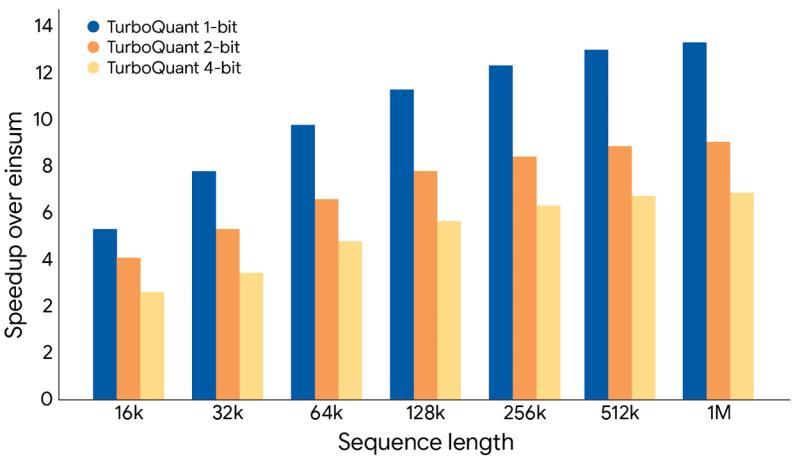
TurboQuant 带来的收益不仅体现在显存占用上,也直接反映在推理吞吐与延迟上。研究团队在不同序列长度下测试了推理速度,结果显示,相比传统实现,TurboQuant 在长序列场景中最高可实现约 8 倍的推理加速。
随着上下文长度增加,KV 缓存读写与计算的成本会迅速上升,而 TurboQuant 通过压缩缓存规模,显著降低了这部分开销,因此在超长上下文下加速效果尤为明显。
■ TurboQuant 对推理速度的影响:序列越长,加速效果越明显,最高可达到约 8 倍的速度提升
面向向量检索与 RAG 的更广泛应用
论文还指出,TurboQuant 的相关技术不仅适用于 LLM 推理阶段的 KV 缓存压缩,也可以推广到向量检索等场景。
在基于 LLM 的检索增强生成(Retrieval-Augmented Generation, RAG)系统中,需要存储和检索海量向量表示,存储成本与检索效率都是关键问题。高效的向量压缩技术能够显著降低存储需求,并提升检索速度。
Google Research 认为,TurboQuant 有望成为支撑未来 AI 基础设施的重要底层技术之一,不仅能优化大模型推理,还可帮助构建更高效的搜索、推荐与知识检索系统。









