

Google 于 2026 年 3 月 10 日(美国时间)正式发布多模态嵌入模型 Gemini Embedding 2,并通过 Gemini API 与 Vertex AI 以公测(Public Preview)形式向开发者开放。该模型能够将文本、图像、视频、音频以及文档等不同类型的数据映射到同一向量空间,用于提升搜索、推荐以及 RAG(Retrieval-Augmented Generation,检索增强生成)等 AI 应用的效果。
在同一向量空间处理文本与图像的嵌入模型
嵌入(Embedding)模型是一类将文本、图像等非结构化数据转换为数值向量的 AI 技术。通过这种方式,系统可以计算不同数据之间的语义相似度,因此被广泛应用于语义搜索、推荐系统、聚类分析、文档分类等众多场景,是现代 AI 系统的基础能力之一。
Gemini Embedding 2 的概念示意:模型将文本、图像、视频、音频、文档等多种数据形式向量化,并映射到统一的「embedding 空间」,从而可以在同一空间中进行比较与检索。
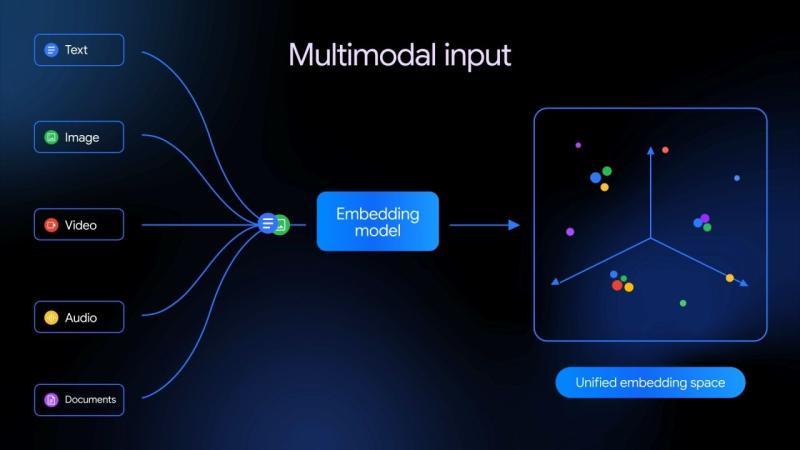
与传统仅支持文本的嵌入模型不同,Gemini Embedding 2 原生支持多模态输入,不仅可以处理文本,还能对图像等多种数据类型进行嵌入。通过将不同模态的数据统一映射到同一向量空间,系统可以:
- 比较图像与文本在语义上的接近程度;
- 从包含图片的数据库中,根据文本或图像查询相关内容;
- 在同一检索系统中综合利用多种数据源进行搜索与推荐。
这类多模态嵌入技术可用于构建更智能的搜索与推荐系统,例如:
- 电商场景中的商品搜索与相似商品推荐;
- 图文混排内容的个性化推荐;
- 支持图片与文档混合检索的企业知识库搜索等。
通过 Gemini API 与 Vertex AI 提供
Gemini Embedding 2 通过 Google 的生成式 AI 平台 Gemini API 与 Vertex AI 对外提供服务。开发者可以在现有应用或企业系统中集成该嵌入模型,用于实现:

- 语义搜索与知识检索功能;
- 多模态内容的相似度计算与推荐;
- 面向内部文档与业务数据的智能问答等。
在构建 RAG(检索增强生成)系统时,嵌入模型是关键组件之一。企业可以先利用嵌入模型从内部文档、数据库中检索出与用户问题高度相关的内容,再将这些检索结果提供给生成式 AI,用于生成更准确、更贴合业务语境的回答。近年来,这一模式已成为企业级 AI 应用的主流架构之一。
Gemini Embedding 2 的基准测试结果显示:在文本、图像、视频、音频等多模态检索任务上,相比既有嵌入模型整体性能更优。
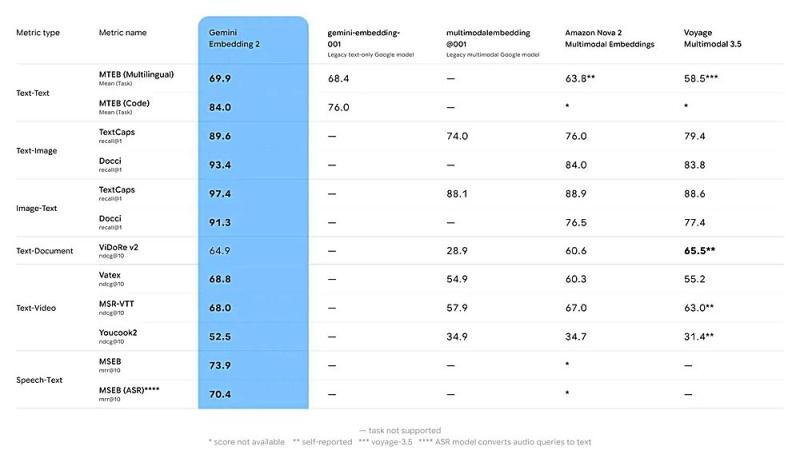
目前,Google 将 Gemini Embedding 2 以公测形式开放,希望在真实业务场景中收集开发者反馈,并在此基础上持续改进模型性能与易用性。
Gemini 模型家族扩展的重要一环
此次发布被视为 Google 扩展 Gemini 模型家族 的重要一步。近年来,Google 围绕 Gemini 系列持续推出面向不同场景的模型能力,包括:
- 文本生成与对话;
- 多模态理解与推理;
- 代码生成与开发辅助等。
在这一体系中,嵌入模型扮演着支撑搜索与知识基座的基础设施角色。随着 Gemini Embedding 2 的引入,Google 旨在进一步强化:
- 搜索系统的语义理解与多模态检索能力;
- 推荐引擎对图文音视频等多源内容的综合建模能力;
- 多模态 RAG 与企业知识管理等信息探索平台的整体水平。
借助统一的多模态向量空间,开发者与企业有望更容易地构建跨文本、图像、视频、音频的智能应用,在搜索、推荐与知识问答等领域实现更高精度与更自然的用户体验。









