

Luma AI 于 2026 年 3 月 6 日(当地时间)正式发布了新一代图像生成模型「Uni-1」。这是一款将“理解能力”和“生成能力”统一到同一模型中的多模态模型,不仅能生成图像,还能在同一架构内处理指令理解和推理任务。Luma AI 将其视为迈向「Unified Intelligence(统一智能)」的第一步。
将理解与生成统一处理的新架构
Uni-1 采用自回归式 Transformer 架构,将文本与图像视作同一序列进行处理。也就是说,模型在生成输出时,会在统一的上下文中同时考虑文字信息和图像信息,从而在“理解指令并推理”与“生成图像”之间实现一体化处理。
根据 Luma AI 的介绍,这种设计使得模型不再只是“画得好看”,而是能够在生成过程中综合考虑指令中各要素之间的关系以及场景的整体逻辑。例如:
- 时间上的前后关系(先后顺序、因果链条)
- 空间上的布局与位置关系
- 场景在逻辑上的自洽性
官方强调,Uni-1 能在同一模型中同时处理这些维度,从而生成在语义和结构上更合理的图像。
在推理能力基准测试中超越既有模型
Luma AI 同时公布了图像生成模型推理能力基准测试「RISEBench」上的评测结果。RISEBench 主要用于衡量模型在以下方面的表现:
- 因果关系理解
- 空间理解
- 时间理解
- 逻辑推理
其核心关注点是:模型在面对复杂、多约束的指令时,能否生成与指令高度一致且逻辑连贯的图像。
■ 图:在 RISEBench 上比较各图像生成模型的推理性能。Uni-1 在综合得分上超过 Nano Banana 2 与 GPT Image 1.5 等模型
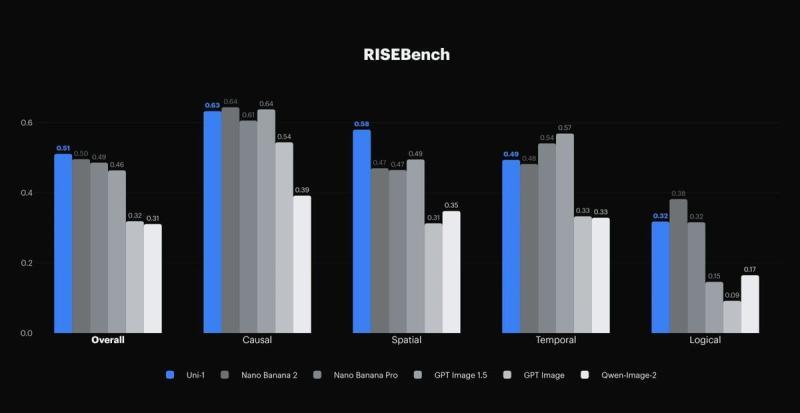
从公开的图表来看,Uni-1 的综合得分为 0.51,高于 Nano Banana 2、GPT Image 1.5 等对比模型。在因果理解、空间理解等细分指标上,Uni-1 也取得了较高分数。Luma AI 借此强调,Uni-1 不仅在图像质量上具备竞争力,在“根据指令构建场景”的推理能力上也具有优势。
同一条件下的生成效果对比
为了更直观地展示差异,Luma AI 还公布了多款图像生成模型在相同提示词(Prompt)下的生成结果对比。例如:
- 场景设定为会议室
- 需要将参考图像中的两只猫合成到会议室场景中
- 一只猫在使用 LumaAI 的幻灯片进行演示
- 另一只猫在一旁观看
- 参考图像中的两位男性坐着观看并对演示作出反应
通过这种包含多个主体与不同角色分工的复杂场景,可以观察各模型在构图一致性、角色关系理解和场景逻辑上的差异。

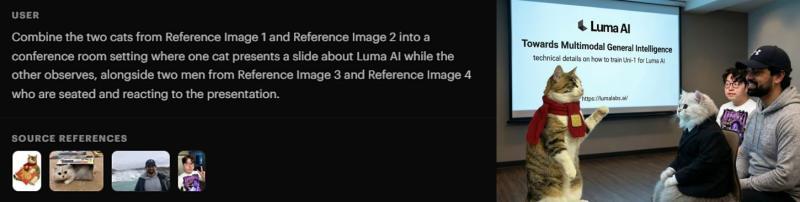
■ 图:同一提示词下各模型的生成结果对比。展示了 Uni-1、Nano Banana 系列以及 GPT Image 1.5 的输出示例
左)提示词:将参考图像中的两只猫合成到会议室场景中。一只猫在展示 LumaAI 的幻灯片,另一只猫在旁边观察。参考图像中的两位男性也坐在一旁,对演示作出反应/右)Uni-1 的输出结果
 左)NanoBanana/右)NanoBanana2
左)NanoBanana/右)NanoBanana2
 左)NanoBanana Pro/右)GPT Image1.5
左)NanoBanana Pro/右)GPT Image1.5

从这些对比示例中可以看到,Uni-1 在人物与动物的空间位置、演示者与观众的角色区分、室内场景的整体构图等方面,表现得相对自然、连贯。Luma AI 将此归因于其“理解与生成一体化”的模型设计。
生成能力反向促进视觉理解
Luma AI 还提出一个观点:具备图像生成能力本身,有助于提升模型的视觉理解能力。为此,官方公布了在物体检测基准「ODinW Dense Detection」上的评测结果。
■ 图:ODinW Dense Detection 准确率。Uni-1 完整模型在精度上超过理解专用模型
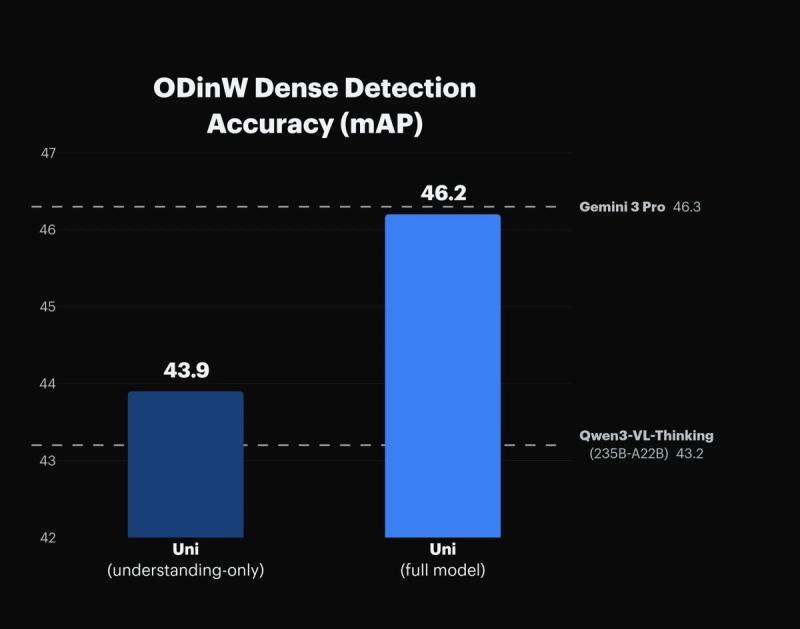
根据公开数据:
- 仅用于“理解任务”的专用模型得分为 43.9
- 具备生成能力的 Uni-1 完整模型得分为 46.2
Luma AI 认为,这一差异表明:为了学会“如何生成图像”而进行的训练,可能也在同时强化模型对物体、空间布局和场景细节的辨别能力,从而在物体检测等视觉理解任务上取得更好表现。
通往「Unified Intelligence」的起点
在定位上,Luma AI 并未将 Uni-1 仅仅视作一款新的图像生成模型,而是强调其跨越“理解”和“生成”边界的特性。官方在发布中提到,未来将进一步结合:
- 世界知识与常识
- 文化语境与背景理解
- 多轮交互中的持续调整能力
Luma AI 将 Uni-1 视为通向更广义多模态 AI 的基础平台,希望在统一的模型中同时处理文本、图像以及更复杂的交互与推理任务,从而逐步迈向其所称的「Unified Intelligence(统一智能)」。









