

OpenAI 于 2026 年 4 月 23 日(当地时间)正式发布最新大模型 GPT-5.5。这一版本被定位为面向“real work(真实工作场景)”的模型:能够理解复杂目标、调用多种工具、自行检查与修正过程,并将任务推进到完成。
GPT-5.5 将率先在 ChatGPT 与 Codex 中提供使用,面向开发者的 API 接口 也将在近期上线。
在知识型工作任务上表现显著提升
GPT-5.5 的核心升级方向,是覆盖广泛的知识劳动场景,包括:
- 代码编写与调试
- 调研与信息收集
- 数据与信息分析
- 文档撰写与编辑
- 表格与数据表(Spreadsheet)制作
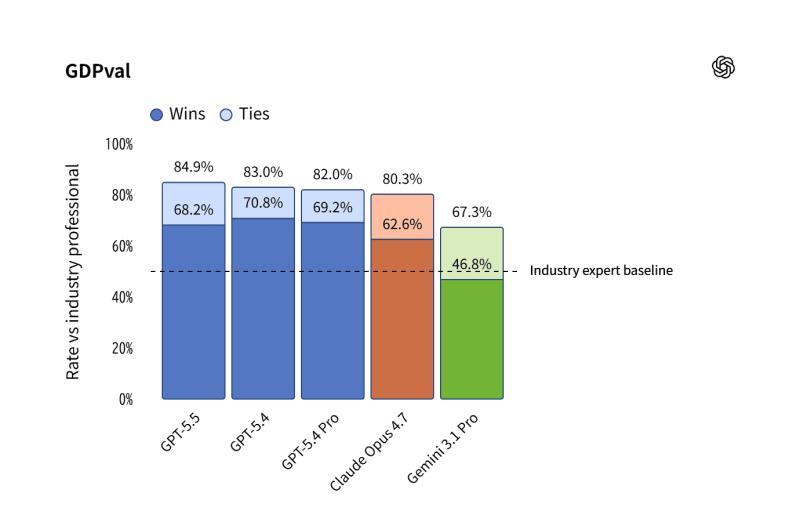
在用于评估知识劳动任务的基准测试 「GDPval」 中,GPT-5.5 取得了 84.9% 的成绩,相比前一代模型以及其他厂商的同类模型,都处于更高水平。
OpenAI 指出,GPT-5.5 相比以往版本,能够:
- 更快理解任务意图
- 在更少指令下做出更合适的行动选择
这意味着用户不必给出过于细致的步骤说明,模型也能较好地“领会需求并主动完成”。
强化工具调用与实际操作能力
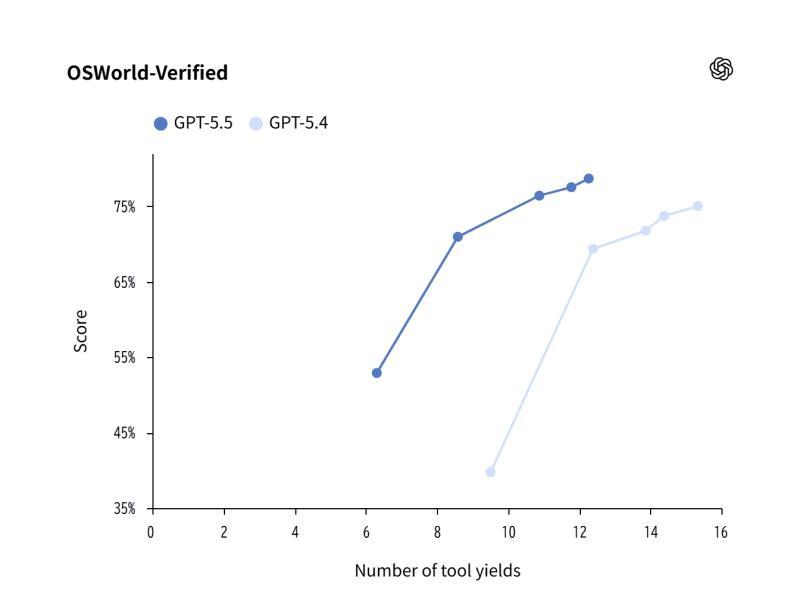
在衡量模型在真实计算机环境中操作能力的基准 「OSWorld-Verified」 上,GPT-5.5 取得了 78.7% 的成绩。
这一测试主要考察模型在以下场景中的综合能力:
- 文件系统操作(如文件管理、移动、重命名等)
- 浏览器操作(如打开网页、搜索信息、填写表单等)
- 将多种工具组合起来完成一项完整任务
GPT-5.5 不再只是“给出答案”的对话模型,而是进一步向 “能主动执行任务的代理型 AI(Agent)” 靠拢:
- 能根据目标选择合适工具
- 在执行过程中自我检查与调整
- 以更高成功率完成多步骤的实际操作任务
面向企业业务流程的高精度表现
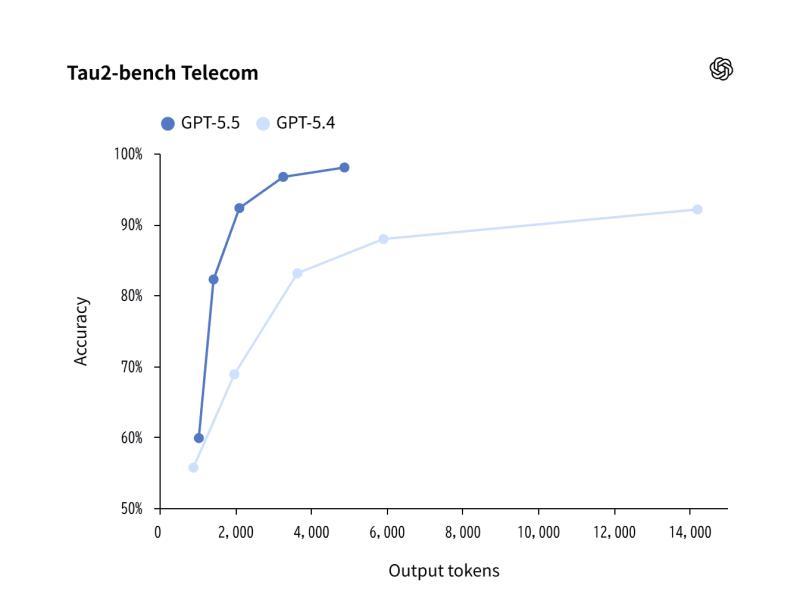
在模拟企业业务流程的基准 「Tau2-bench Telecom」 中,GPT-5.5 的准确率达到 98.0%。
该基准主要复现诸如客户服务等真实业务场景,考察模型在:
- 多轮对话与信息收集
- 多步骤判断与决策
- 按流程执行复杂业务规则
等方面的稳定性与一致性。
测试结果显示,GPT-5.5 能在跨多个步骤的任务中保持较高的一致性和准确率,适合嵌入到企业的实际业务流程中,用于:

- 客服与咨询自动化
- 业务流程辅助决策
- 内部流程自动化与质检
OpenAI 因此将 GPT-5.5 明确定位为 可直接融入企业工作流的生产级模型。
代码能力升级,进一步支持开发者场景
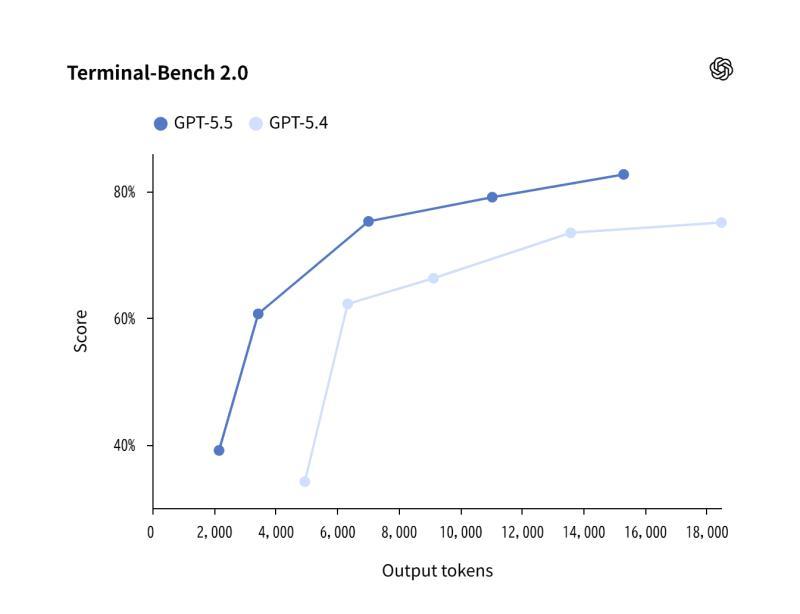
在评估代码能力的基准 「Terminal-Bench 2.0」 中,GPT-5.5 的得分超过了上一代 GPT-5.4。
该基准更贴近真实开发环境,重点考察:
- 代码生成与重构
- Bug 定位与修复
- 在命令行环境中的综合操作能力
结果显示,GPT-5.5 在代码生成质量、修改准确性以及调试效率方面都有明显提升。
OpenAI 此前在 4 月披露,Codex 的周活跃开发者数量已超过 300 万,随后两周内又增长到 400 万以上。在这一快速扩张的开发者生态中,GPT-5.5 将作为 开发者向 AI 代理的核心基础模型,支撑:
- 日常开发辅助
- 自动化代码维护
- 项目级别的智能协作
在 ChatGPT 与 Codex 中率先上线,并面向专业用户扩展
在 ChatGPT 中,OpenAI 将提供两个面向不同需求的 GPT-5.5 版本:
-
GPT-5.5 Thinking:
- 侧重在复杂问题上给出更快、更简洁的回答
- 适合调研、分析、快速决策等场景
-
GPT-5.5 Pro:
- 在回答的全面性、结构化程度和准确性方面有大幅提升
- 面向商务、法律、教育、数据科学等对严谨性要求较高的专业领域
对于开发者与企业用户,OpenAI 也公布了 GPT-5.5 的 API 价格:
- 输入:每 100 万 tokens 收费 5 美元
- 输出:每 100 万 tokens 收费 30 美元
API 的具体开放时间标注为 “coming soon”,意味着将在近期逐步向外部用户开放接入。
安全性评估与生物安全漏洞奖励计划
OpenAI 同时发布了 GPT-5.5 的 System Card,详细说明了该模型的设计目标与适用范围,包括:
- 复杂实务处理
- 在线调研与信息分析
- 文档与表格制作
- 跨工具协同作业
在安全性方面,OpenAI 启动了 GPT-5.5 Bio Bug Bounty 计划,聚焦生物领域相关风险的验证与防护:
- 面向具备 AI 红队测试、安全与生物安全经验的研究人员
- 征集可突破生物安全防护机制的通用“越狱”方法
- 最高奖励金额为 25,000 美元
通过这一计划,OpenAI 试图在持续提升模型能力的同时,加强对高风险领域(尤其是生物安全)的防护与外部审查机制。









