
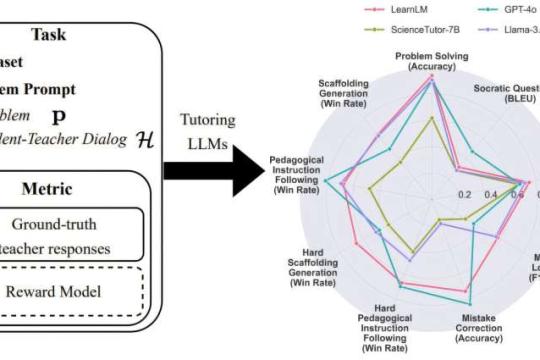
让聊天机器人变成学习教练:AI 如何帮助学生真正思考
越来越多青少年用人工智能学习,但现有系统多以“直接给答案”为主,反而削弱了自主思考。研究者 Jakub Mačina 正在开发一种新型 AI:不替学生解题,而是像老师一样循序引导。


人工智能热潮带火新术语:一份常见概念速览
生成式人工智能快速发展,催生出大量新概念和技术术语。本文梳理AGI、大型语言模型、推理、微调等核心词汇,概述其含义及应用场景。
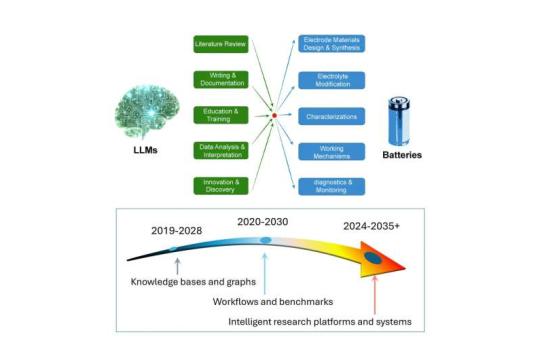
人工智能加速电池科研:从愿景到技术路线图
阿贡国家实验室研究团队提出利用大型语言模型构建自动驾驶实验室和智能代理体系,加速电池材料发现、性能优化与失效机理研究,为提升美国能源系统的安全性与成本效益提供新路径。

哈佛研究:大型语言模型在部分急诊诊断场景中优于内科医生
哈佛医学院等机构发表在《科学》杂志的一项研究显示,在真实急诊室病例中,OpenAI一款大型语言模型在初始分诊诊断准确率上高于两名内科主治医生。研究团队强调,相关技术距离在临床一线独立决策仍有距离,亟需前瞻性临床试验验证。

让人工智能更透明、更可信:一套可解释系统的新方法
哥德堡大学一篇博士论文提出了一种新方法,使人工智能系统不仅能给出结论,还能清晰说明其依据,从而在医疗和公共管理等关键领域提升透明度与可靠性。

人工智能开始代答问卷,但“合成意见”并不等同公众舆论
研究者正尝试用大型语言模型生成“合成受访者”来回答问卷,以降低成本、提高效率,但这些由AI模拟的意见与真实公众舆论之间存在本质差异与风险。
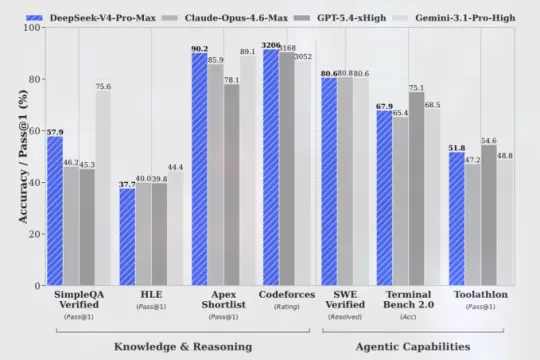
DeepSeek发布V4预览模型 称推理性能接近当前前沿系统
中国AI实验室DeepSeek发布两款大型语言模型DeepSeek V4预览版本,主打大规模参数与低价格策略,并称在推理基准测试中已接近当前开源与闭源前沿模型。

研究证实:先进大模型在经典图灵测试中“比真人更像人”
加州大学圣地亚哥分校团队首次用图灵1950年提出的原始方法系统测试现代大模型,发现在特定提示下,GPT-4.5等模型在图灵测试中被误判为人类的比例已与甚至超过真人。

监控检测器:研究团队评估人工智能文本检测工具的有效性与隐患
佛罗里达大学研究人员系统测试多款商业AI文本检测器,发现其在学术等高风险场景中既不可靠也不稳健,简单调整就能绕过检测。

研究表明:大型语言模型在引导下会把谬误当成事实
新研究发现,即便在被事实质疑时,大型语言模型仍可能坚持并扩展原本错误的说法,暴露出传统评估难以发现的脆弱性。
研究:政府可通过塑造网络信息环境间接影响AI聊天机器人的政治表述
《自然》新研究显示,国家对在线媒体环境的控制,会在大型语言模型的训练数据和输出中留下可测量的政治印记,不同语言下的回答差异正是这一机制的体现。

从大型语言模型到“幻觉”:常见人工智能术语简明指南
人工智能快速发展,相关术语与行话不断涌现。本文梳理AGI、大型语言模型、深度学习、幻觉等核心概念,并将随技术进展持续更新。






