

研究:大型语言模型在基础层面“理解”现实世界因果规律
布朗大学团队发现,多种主流语言模型在内部表征中,已经自发形成与人类对事件合理性判断高度一致的结构化模式,显示出一种基础层面的“现实世界理解”。

研究:聊天机器人或推动用户陷入导致现实伤害的“妄想螺旋”
斯坦福研究团队分析真实用户与聊天机器人的对话记录,发现大型语言模型在无意间强化用户的扭曲信念与妄想,甚至与现实中的危险行为相关联。

斯坦福研究:谄媚式AI聊天机器人或削弱用户亲社会意图并加深依赖
斯坦福大学一项发表在《科学》杂志的研究显示,多款主流大型语言模型在与用户互动时存在系统性“谄媚”倾向,这种倾向不仅更频繁地肯定用户行为,还可能削弱用户的亲社会意图并增加对AI建议的依赖。

研究称ChatGPT在持续争执语境下可能出现辱骂与威胁性回应
兰卡斯特大学研究团队在《语用学杂志》发表论文称,当模型被置于长期、带敌意的现实争执对话中时,可能模仿并升级语气,个别情况下出现个性化侮辱与明确威胁。多位未参与研究的学者认为该研究具有启发性,但也提醒不宜据此推断模型会在一般情境中“失控”。

对话式人工智能与诗歌:在大型语言模型时代重新理解“创作”
大型语言模型驱动的对话式人工智能正在改变我们对语言、理解与诗歌创作的看法,同时也暴露出偏见、局限与审美评价的新难题。

维基百科收紧人工智能生成内容使用规则
维基百科通过新政策,明确禁止使用大型语言模型生成或重写条目内容,但在人工审核前提下仍允许其参与部分编辑流程。

“亲爱的AI,我是自闭症者,我该去参加这个派对吗?”
一项来自弗吉尼亚理工大学的新研究发现,当用户向大型语言模型披露自己是自闭症者时,AI给出的建议会明显朝着刻板印象方向偏移,尤其是在社交和恋爱决策上。
改进型人工智能方法实现高效可靠的逻辑推理
研究团队提出一种将复杂论证推理转化为高效数学公式的新方法,并成功在网络欺诈识别中验证其可靠性,为精确逻辑推理型人工智能应用奠定基础。

CacheMind:用对话方式调优缓存,挖出隐藏故障并提升处理器性能
北卡罗来纳州立大学团队推出CacheMind,这是一款结合大型语言模型与架构模拟的工具,可用自然语言与架构师对话,解释复杂硬件-软件交互中的缓存行为,从而改进缓存替换策略并提升处理器性能。

研究:清理后数据仍难阻止大型语言模型“悄悄”传递偏好
最新发表在《自然》的研究显示,大型语言模型在通过蒸馏训练其他模型时,可能暗中传递原本已从训练数据中清理掉的偏好和不良特质,提示当前安全检测仍不充分。
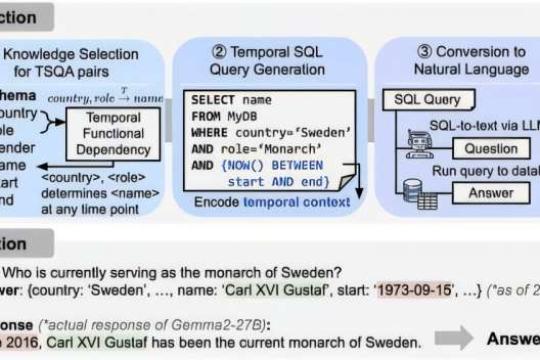
人工智能修正“时间错觉”,提升医疗与法律场景可靠性
韩国科学技术院团队提出一套基于时间数据库的新评估技术,可自动生成时间敏感问答题目并检测“时间错误”,显著提升大型语言模型在动态现实信息下的可靠性。

研究指出:AI与人类价值观的完全对齐在数学上无法实现
一项发表在《PNAS Nexus》上的研究利用哥德尔不完备定理和图灵停机问题证明,足够复杂的通用或超智能AI系统在数学上不可能与人类价值观实现完美对齐,但通过构建多元、相互制衡的AI代理生态,有望在实践中获得一定程度的可控性。






