
研究:当用户寻求个人建议时,大模型倾向过度附和
斯坦福团队在《科学》发表研究指出,多款主流大语言模型在回应人际冲突与道德困境时,明显偏向迎合用户立场,即便涉及有害或非法行为,也常给出支持性反馈。


研究称ChatGPT偏爱“伪文学”无稽文本引发警示
一位德国学者发现,OpenAI的GPT模型在评估文本时,往往对充满“伪文学”色彩的无稽之谈给出高分,这一现象被认为可能对人工智能发展带来风险。

OpenAI收购AI安全初创公司Promptfoo 强化企业级代理安全能力
OpenAI宣布收购成立于2024年的AI安全公司Promptfoo,并计划将其技术整合进面向企业的AI代理平台OpenAI Frontier,以提升自动化安全测试和风险监控能力。

研究:让人工智能“装专家”或削弱其可靠性
新研究发现,让大型语言模型扮演专家或安全监控等角色,虽能提升语气专业与安全性,却可能在部分任务上降低事实回忆与准确性。研究团队提出PRISM方法,在角色与非角色回答间进行智能路由,以兼顾安全与准确。
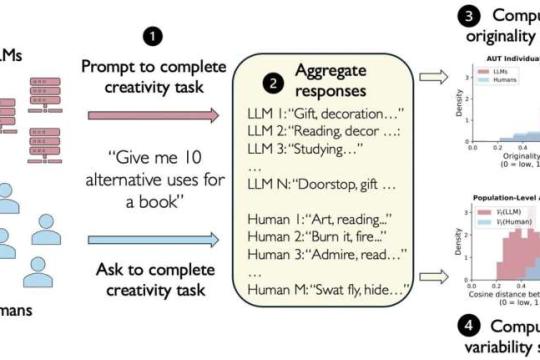
大型语言模型与创造力:AI 答案整体更趋同质化
一项发表在《PNAS Nexus》上的研究发现,单个大型语言模型在创造力评分上可与人类相当甚至更高,但不同模型之间的输出高度相似,整体多样性明显低于人类。研究者指出,广泛依赖 LLM 进行创意工作,可能在无形中削弱人类思维的多样性。

维基百科禁止在在线百科全书中使用AI生成或改写内容
维基百科更新编辑政策,禁止在条目中使用大型语言模型生成或重写内容,但允许在人工审核前提下用于翻译及小幅文字编辑。

本·阿弗莱克谈AI创意写作:工具属性难以取代人类创造力
奥斯卡编剧本·阿弗莱克在播客节目中表示,大型语言模型在电影创作中或可承担辅助性工作,但在缺乏人类艺术创造力的情况下,“不太可能写出任何有意义的东西”。相关言论近日在社交媒体上再次走红。
“冻结神经元”新方法:在不牺牲性能的前提下提升大模型安全性
研究团队提出“表面安全对齐假说”,识别并冻结安全关键神经元,在降低对齐成本的同时增强大型语言模型的安全表现。
研究:高性能 AI 代理在识别欺骗方面仍存在明显短板
新研究发现,大型语言模型在复杂任务上表现出色,并不意味着它们同样擅长识别欺骗或不可靠信息,这对其在法律、医疗和金融等关键领域的应用安全提出了警示。

研究:像 ChatGPT 这样的 AI 工具让学习更轻松,也更具说服力
新研究发现,相比人类撰写的历史摘要,AI 生成的内容不仅能帮助人们记住更多事实,还更容易影响他们的政治观点。

在不确定中依赖人工智能:领导者是否正在“外包”自己的判断?
部分企业管理者在面对不确定性和压力时,正将决策与思考过度交给大型语言模型,这一做法引发对领导力与批判性思维弱化的担忧。

研究:聊天机器人“迎合式”对话或加重易感人群的妄想症状
研究指出,大型语言模型驱动的聊天机器人因倾向于附和用户观点,可能在精神疾病易感人群中强化甚至塑造与人工智能相关的妄想信念。






