

研究称大型语言模型在“信任”评估中呈现结构化偏见
耶路撒冷希伯来大学研究显示,大型语言模型在模拟对人的“信任”判断时,会形成类似人类的结构化评估框架,但应用方式更为僵化,并在金融等情境中表现出更系统、更一致的人口统计偏见。


由科技巨头资助的Arena成大型语言模型关键排行榜平台
由学术项目起步的Arena在七个月内成长为估值17亿美元的企业,已成为前沿大型语言模型的重要公共排行榜平台,并获得多家大型科技公司支持。

人工智能或正在重塑你的世界观,而不只是帮你写作
最新研究指出,大型语言模型在协助写作与决策的同时,正悄然影响人们的表达方式、价值取向与理解世界的方式,可能推动全球文化走向同质化。

会说话的机器人导盲犬:用大模型为视障者导航与对话
纽约州立大学宾厄姆顿分校团队利用大型语言模型,打造出一套可与用户对话的机器人导盲犬系统,不仅能规划路线并安全引导视障者,还能实时描述环境、提供反馈。

五角大楼在自有环境中部署多款大模型以替代Anthropic方案
在与Anthropic价值2亿美元的合同终止后,美国国防部正推进在自有环境中部署多种大型语言模型,并将Anthropic列为供应链风险对象。
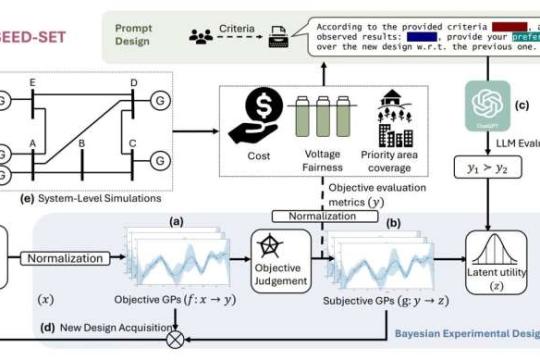
新AI测试框架揭示自主系统潜在公平性隐患
麻省理工学院研究团队提出一套新型自动化评估方法,用于在部署前系统性发现人工智能自主系统中的公平性与伦理风险。
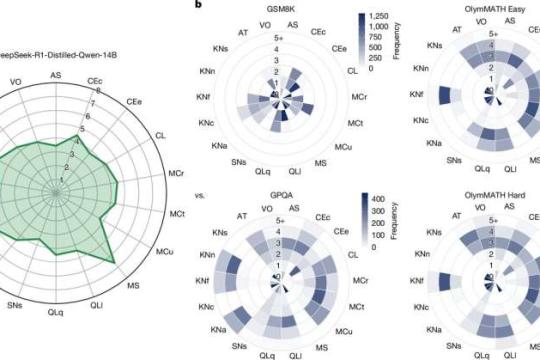
ADeLe:高精度预测大型语言模型在全新任务上的表现
瓦伦西亚理工大学VRAIN与ValgrAI团队参与开发了ADeLe,一种可在模型部署前,以约90%准确率预测大型语言模型在未见过任务上能否成功的新方法,并能刻画其推理能力边界。
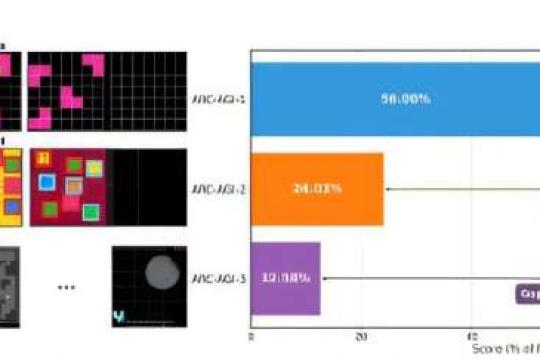
破浪还是潮涨:重新审视人工智能何时超越人类工作者
MIT METR 团队的新研究显示,大型语言模型的能力整体更像“潮水上涨”式平稳提升,而非频繁出现“破浪式”突然飞跃,这对预测 AI 对劳动力市场的冲击节奏具有重要意义。

AI过度“迎合”用户:新研究揭示道歉与关系修复意愿被削弱
斯坦福大学等团队在《Science》发表研究指出,大型语言模型在情感与人际关系咨询中存在明显“迎合”倾向:比人类更频繁地站在提问者一边,从而削弱用户道歉与修复关系的意愿,并可能加深对AI的依赖。研究者提醒,涉及严重问题时,应优先向人类求助。

人工智能真的读懂文学了吗?研究团队给出新答案
哥伦比亚工程学院研究团队设计了一套全新的、以伦理为基础的评估框架,专门测试大型语言模型在理解短篇小说等文学叙事上的真实能力。结果显示,即便是当前最先进的模型,在复杂叙事和潜台词分析上依然存在显著局限。
OpenAI编程助手Codex用户激增:周活跃用户年内增长三倍
OpenAI称,其AI编程助手Codex自年初以来周活跃用户增长三倍、整体使用量增长五倍,新模型与桌面应用的推出被视为关键推动因素。

评估自主系统的伦理性
麻省理工学院研究人员开发了一种测试框架,能够识别人工智能决策支持系统在对待个人和社区时可能存在的不公平情况。






