
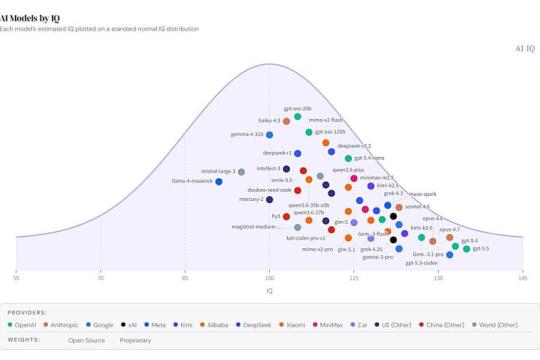
AI模型评估项目「AI IQ」上线:用“IQ”刻度比较 GPT-5.5、Claude Opus 4.7 等前沿模型
工程师兼创业者 Ryan Shea 推出 AI 模型评估项目「AI IQ」,尝试将多种公开基准测试结果统一映射到类似人类 IQ 的直观刻度上,并同时展示模型的推理能力、情绪智力(EQ)与使用成本。


ARC奖基金会发布新一代AI基准测试 ARC-AGI-3 聚焦“流动智能”
由弗朗索瓦·肖莱与Zapier联合创始人迈克·努普共同创立的ARC奖基金会推出新一代基准测试ARC-AGI-3,旨在衡量AI系统在陌生环境中的即时推理与适应能力,被部分业内人士视为检验通用人工智能(AGI)进展的重要参考。

由科技巨头资助的Arena成大型语言模型关键排行榜平台
由学术项目起步的Arena在七个月内成长为估值17亿美元的企业,已成为前沿大型语言模型的重要公共排行榜平台,并获得多家大型科技公司支持。

Google 发布 Gemini 3.1 Pro:以“Deep Think 级推理”树立复杂问题求解新基准
Google 推出最新大模型 Gemini 3.1 Pro,将研究模型 Gemini 3 Deep Think 的核心推理能力下放到通用与企业场景,在 ARC-AGI-2 中取得 77.1% 的成绩,同时保持一线的软件开发与代码生成性能。
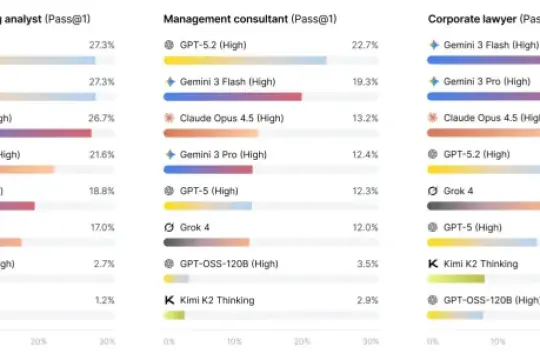
新基准测试显示:主流人工智能代理距离胜任白领工作仍有差距
训练数据公司 Mercor 发布 APEX-Agents 基准,模拟咨询、投行和法律等专业服务场景测试主流模型表现,结果显示目前尚无模型能在这些真实任务中达到可替代专业人士的水平。

研究称人工智能代理在数学上被证明无法完成真实工作
人工智能代理(AI agents)近来被不少厂商描绘为可替代部分人力的“数字员工”,应用场景涵盖客户支持、软件项目管理乃至企业运营。不过,最新一波研究与讨论将焦点从“是否被过度营销”转向更基础的问题:基于当今大型语言模型(LLM)构建的代理系统,是否在数学层面存在难以跨越的可靠性上限,导致其难以稳定完成端到端的真实工作流程。 形式化证明引发争议 争议的起点是一项形式化证明,研究对象直指以大型语言模






