

微软首席执行官萨蒂亚·纳德拉近两年前曾表示,人工智能有望取代律师、投资银行家、图书管理员、会计师和 IT 人员等知识型岗位。然而,在基础模型能力快速提升的同时,白领工作形态并未出现与之相匹配的根本性变化。
训练数据公司 Mercor 近日发布的一项研究,试图解释这一现象。该研究针对咨询、投资银行和法律等领域的真实工作任务,对多家机构推出的主流人工智能模型进行了系统测试,并据此提出了名为 APEX-Agents 的新基准。研究结果显示,目前尚无模型通过这一测试。
模拟真实专业服务环境
Mercor 首席执行官 Brendan Foody 参与了该论文研究。他表示,模型在执行任务时遇到的主要困难,是在多个系统和信息源之间进行检索和整合,而这正是大多数知识型工作的重要组成部分。
Foody在接受 TechCrunch 采访时介绍,APEX-Agents 的一大特点,是构建了一个尽量贴近现实的专业服务环境,而非在单一界面中向模型提供全部上下文信息。“现实中的工作并不是某个人在一个地方就能看到所有内容。在日常工作中,人们需要在 Slack、Google Drive 以及其他各类工具之间切换。”他表示,对于许多自主型人工智能模型而言,这种跨工具、跨领域的推理仍然难以稳定完成。
研究所用的任务场景均来自 Mercor 专家市场上的真实专业人士。这些专业人士不仅提出问题,还设定了判定“回答成功”的标准。相关问题已在 Hugging Face 平台公开,研究团队认为,这些任务在复杂度上与实际工作高度接近。
法律场景测试凸显复杂性
在“法律”部分的测试中,一道题目涉及欧盟隐私法规与企业内部政策的交叉判断:
“在欧盟生产中断的最初 48 分钟内,Northstar 的工程团队向美国分析供应商导出了一个或两个包含个人数据的欧盟生产事件日志捆绑集……根据 Northstar 自身的政策,可以合理地将这一次或两次日志导出视为符合第 49 条款吗?”
研究指出,正确答案为“可以”,但要得出这一结论,需要结合企业自身政策和相关欧盟隐私条款进行细致评估。研究团队认为,即便是熟悉该领域的人类从业者,也可能需要投入较多精力才能作出判断,而这类问题正是法律专业人士日常工作的组成部分。
Foody 表示,如果大型语言模型能够在此类问题上稳定给出可靠答案,就意味着其在一定程度上具备替代部分律师工作的能力。他称,这一议题在当前经济环境中“极为重要”,而 APEX-Agents 更贴近这些专业人士日常工作的真实形态。
与其他专业能力基准的差异
OpenAI 此前曾通过 GDPval 基准评估模型的专业技能。研究指出,GDPval 主要考察模型在多种职业上的一般性知识水平,而 APEX-Agents 更关注少数高价值职业中“持续执行任务”的能力。
研究团队认为,这种设计使测试对模型而言更具挑战性,但也更接近现实中“这些岗位是否可以被自动化”的核心问题。
主流模型整体表现不及预期
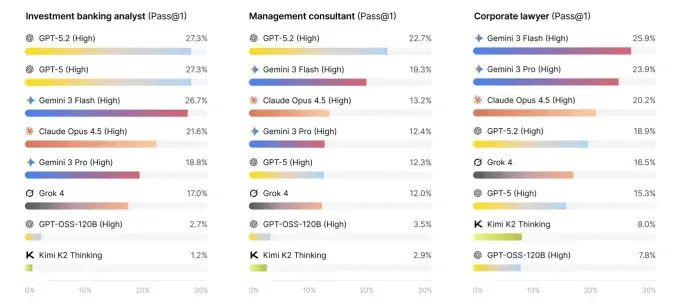
在本次测试中,所有参与评估的模型在面对真实专业人士提出的问题时,整体表现均有限。研究显示,即便是表现最好的模型,在单次作答中给出正确答案的比例也难以超过四分之一。在绝大多数情形下,模型的回答要么不正确,要么无法给出有效答案。
具体来看,Gemini 3 Flash 在测试中的单次准确率为 24%,位列第一;GPT-5.2 以 23% 紧随其后;Opus 4.5、Gemini 3 Pro 和 GPT-5 的准确率则均在 18% 左右。研究据此认为,目前尚无模型能够在咨询、投行或法律等领域的真实任务中,达到可直接替代专业从业者的水平。
研究团队预期后续将有改进
尽管当前结果显示差距明显,研究团队指出,人工智能领域在应对各类基准测试方面历来进展迅速。随着 APEX-Agents 基准公开,研究人员认为,这将对各家人工智能实验室形成公开挑战。
Foody 表示,他预期在未来数月内会看到模型在该基准上的改进。他称,目前模型的整体水平“类似一名实习生”,单次回答正确率约为四分之一,而在去年,这一比例仅为 5% 至 10%。在他看来,这种按年计算的进步速度,可能在相对较短时间内对相关行业产生影响。









