

工程师兼创业者 Ryan Shea 于 2026 年 5 月 12 日正式公开了 AI 模型评估项目「AI IQ」。该项目旨在持续追踪主流前沿 AI 模型,并将其能力用类似人类 IQ 的直观刻度进行量化和展示。
目前纳入评估的模型包括 GPT-5.5、Claude Opus 4.7、Gemini 3.1、Grok 4.3、Kimi K2.6、Qwen 3.6、DeepSeek V4 等一系列前沿大模型。AI IQ 基于多种公开基准测试结果,给出模型的推定 IQ、EQ(情绪智力)、实际使用成本,并可视化不同厂商前沿模型随时间演进的趋势。
Shea 在自己的发布文章中指出,随着模型数量和版本快速增加,仅靠零散的基准测试表格或产品发布时的口碑,已经难以把握 AI 模型整体演进情况。因此,他在 X 上将 AI IQ 介绍为“用人类 IQ 刻度展示前沿 AI 模型”的项目。
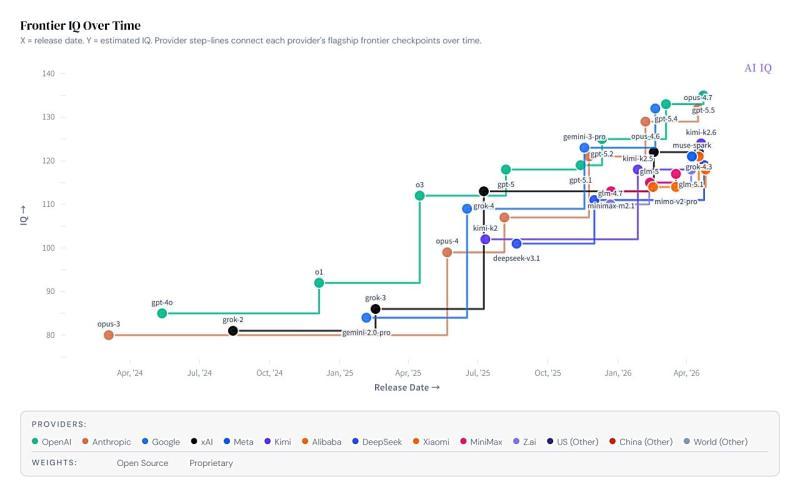
18 种基准测试划分为 5 大推理领域,统一换算为推定 IQ
AI IQ 的核心做法,是收集各模型在公开基准测试中的原始得分,然后依据难度曲线,将这些分数映射到统一的 IQ 刻度上。评估维度被划分为 5 个推理领域:
- 流动性抽象推理
- 数学推理
- 程序(代码)推理
- 批判性推理
- 代理(Agent)推理
在其方法说明中,AI IQ 将 18 种不同的基准测试归类到上述 5 大推理领域,并据此计算每个模型的综合 IQ(Composite IQ)。综合 IQ 为 5 个领域得分的平均值,但仅对至少在其中 2 个领域有数据的模型进行计算。对于缺失数据的领域,AI IQ 会在内部评分流程中采用相对保守的方式进行补全。
参与换算的基准测试包括 ARC-AGI、FrontierMath、AIME、GPQA Diamond、SWE-Bench Verified、Humanity’s Last Exam、BrowseComp、Terminal-Bench、Tau2-Bench 等。AI IQ 并非简单罗列各项原始分数,而是尝试将不同类型的能力评估统一到一个可比较的刻度上,从而更直观地对比模型间的整体能力水平。
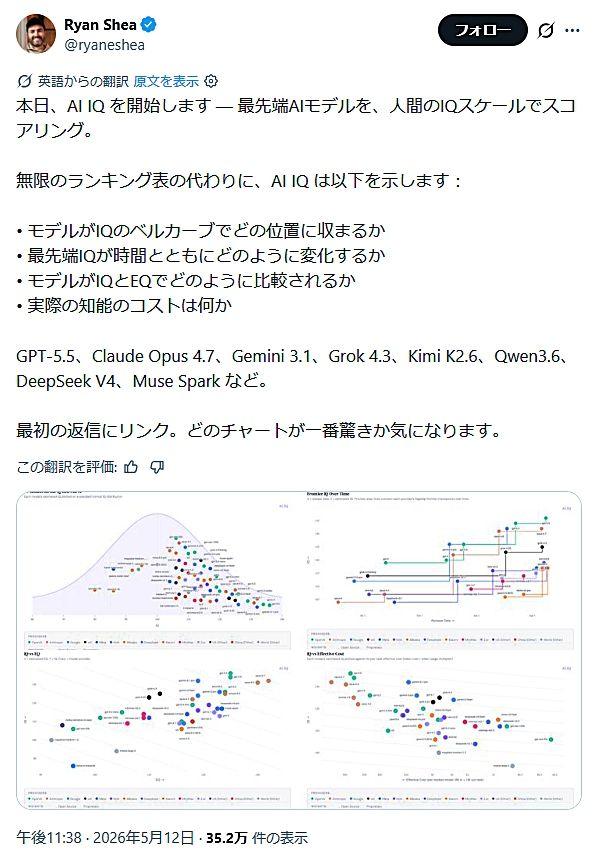
用时间轴展示前沿模型能力演进
AI IQ 还提供了按时间维度展示模型推定 IQ 的功能。用户可以查看各家前沿模型在不同发布时间点上的推定 IQ 变化,从而把握模型迭代带来的能力提升趋势。
在 AI IQ 的 IQ 页面中,横轴为模型的公开日期,纵轴为推定 IQ,用折线或点状图展示各家前沿模型随时间的演进轨迹。这样不仅能看到某一时点的“排行榜”,也能观察同一系列模型在不同代际之间的能力跃迁。
通过这种时间序列视图,用户可以更清楚地比较不同厂商在各个阶段的模型大致处于什么水平。随着 AI 性能竞争愈发复杂,AI IQ 试图将原本零散的基准测试结果,转化为更易理解的时间轴叙事。
不仅看 IQ,还可对比实际成本与 EQ
AI IQ 不只展示推定 IQ,还将模型的“实效成本”一并可视化,帮助用户在性能与价格之间做权衡。用户可以在同一张图上同时查看高 IQ 模型与低成本模型的位置。
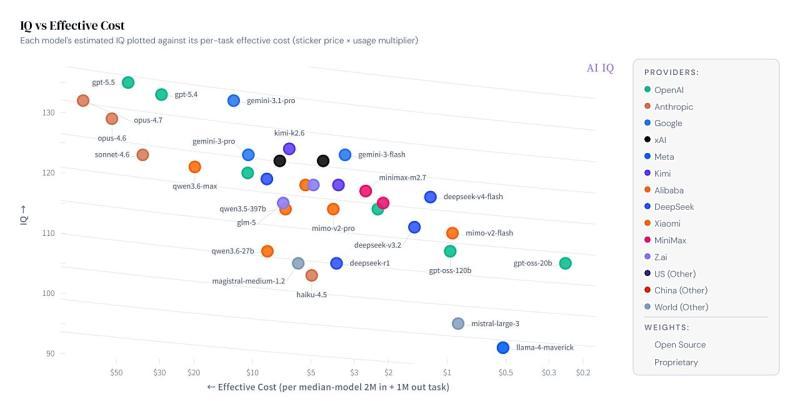
所谓“实效成本”,在 AI IQ 的说明中,是以 200 万输入 Token 与 100 万输出 Token 的工作负载为基准,计算对应的 Token 成本,再乘以一定的使用量系数得出。网站会将各模型的推定 IQ 与这一成本指标进行散点图展示,方便用户评估性能与费用的性价比。
此外,AI IQ 还给出模型的 EQ 推定值。EQ 主要基于 Text Arena Elo 与 EQ-Bench 3 Elo 两项指标计算而来。网站提供 IQ 与 EQ 对比视图,以及将 IQ、EQ 与成本三者以 3D 形式呈现的页面,帮助用户从多维度理解模型特性。
“IQ”只是比喻性参照框架,并非对 AI 智能的绝对测量
从本质上看,AI IQ 是尝试将公开基准测试结果映射到类似人类 IQ 的刻度上,以便更直观地比较不同模型的能力。但这并不意味着它在“像人类智力测验那样”对 AI 的智能进行绝对评定。
AI 模型评估本身会受到多种因素影响,例如:选用哪些基准测试、难度如何设定、是否存在训练数据污染、模型是否针对特定评测进行过优化、缺失数据如何补全等。AI IQ 在其方法说明中也明确列出了这些前提与局限。
因此,更准确的理解是:AI IQ 并不是要给每个模型贴上一个绝对的“智商分数”,而是尝试把分散在各处的公开基准测试结果,转换为一个更易阅读、便于横向比较的统一坐标系。在 AI 模型性能竞争日益激烈、指标体系愈加复杂的背景下,如何呈现和解读这些评估结果,本身也正在成为理解 AI 发展进程的重要议题。









