

让人工智能更透明、更可信:一套可解释系统的新方法
哥德堡大学一篇博士论文提出了一种新方法,使人工智能系统不仅能给出结论,还能清晰说明其依据,从而在医疗和公共管理等关键领域提升透明度与可靠性。


研究证实:先进大模型在经典图灵测试中“比真人更像人”
加州大学圣地亚哥分校团队首次用图灵1950年提出的原始方法系统测试现代大模型,发现在特定提示下,GPT-4.5等模型在图灵测试中被误判为人类的比例已与甚至超过真人。

研究表明:大型语言模型在引导下会把谬误当成事实
新研究发现,即便在被事实质疑时,大型语言模型仍可能坚持并扩展原本错误的说法,暴露出传统评估难以发现的脆弱性。

该不该点“接受Cookies”?研究称拒绝或削弱开放网络
越来越多用户选择拒绝或屏蔽互联网Cookies,但一项大规模实证研究发现,这种做法可能显著削弱依赖广告维持运转的免费开放网络。
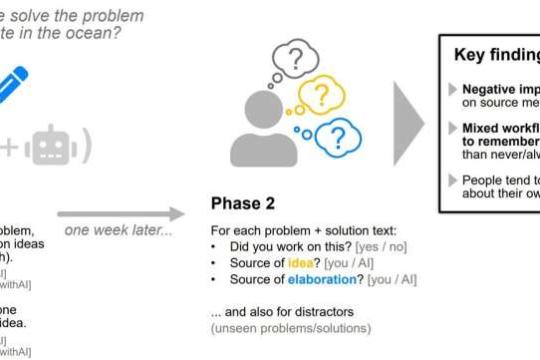
研究:一周后人们难以记住内容是否由人工智能生成
欧盟即将实施AI内容标注规定,但最新研究显示,人们在短短一周后就难以准确回忆内容是否由人工智能生成,这对监管、教育和AI系统设计提出了新挑战。

研究:大型语言模型在内容审核中暗藏政治偏见
昆士兰大学团队发现,大型语言模型在扮演不同政治角色时,会在不显著影响整体准确率的前提下,引入稳定的一致性意识形态偏见,从而影响在线仇恨内容审核的公正性。

研究:人工智能与人类协作优于单独取代人类
新研究表明,人工智能最具价值的应用在于强化人类思考与决策,而不是完全替代人类。通过将AI的运算能力与人类的创造力和判断力结合,可在多领域显著提升知识创造与传播效果。
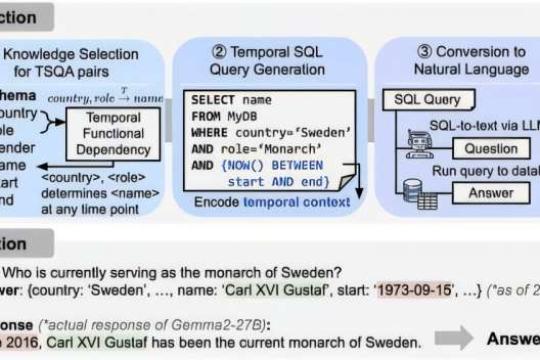
人工智能修正“时间错觉”,提升医疗与法律场景可靠性
韩国科学技术院团队提出一套基于时间数据库的新评估技术,可自动生成时间敏感问答题目并检测“时间错误”,显著提升大型语言模型在动态现实信息下的可靠性。

研究:用户对数据泄露的负面反应消退比预期更快
新研究发现,即便在严重数据泄露事件后,用户对平台的不信任和愤怒情绪会在数月内明显减弱,最终与未受影响用户几乎无异。

研究:人工智能伴侣或缓解孤独,却可能在长期加重心理痛苦
一项基于Reddit数据与深度访谈的长期研究发现,AI伴侣在提供持续情感支持的同时,可能提高人们对现实人际关系的“心理成本”,让用户逐渐疏远他人,并在语言中表现出更多孤独和痛苦迹象。

研究称ChatGPT偏爱“伪文学”无稽文本引发警示
一位德国学者发现,OpenAI的GPT模型在评估文本时,往往对充满“伪文学”色彩的无稽之谈给出高分,这一现象被认为可能对人工智能发展带来风险。
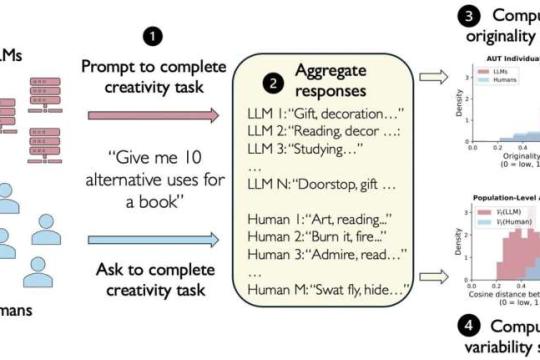
大型语言模型与创造力:AI 答案整体更趋同质化
一项发表在《PNAS Nexus》上的研究发现,单个大型语言模型在创造力评分上可与人类相当甚至更高,但不同模型之间的输出高度相似,整体多样性明显低于人类。研究者指出,广泛依赖 LLM 进行创意工作,可能在无形中削弱人类思维的多样性。






