

大型语言模型(LLM)是一类能够处理并生成多种语言文本的人工智能系统,如今已被全球大量用户日常使用。由于它们可以快速检索信息,并为特定目的生成高度可信的内容,LLM 也逐渐被引入部分专业场景,用于辅助获取法律、医疗或金融相关信息。
然而,目前仍不清楚,这些模型在多大程度上能够可靠且安全地帮助人类做出重要决策。若要为用户在关键选择上提供建议,模型不仅需要判断信息是否可信,还要能基于证据构建有说服力的论证。这两种能力分别被称为“警觉性”(对信息可靠性的识别能力)和“说服力”(影响他人决策的能力)。
来自麦克马斯特大学、向量研究所、不列颠哥伦比亚大学(UBC)、普林斯顿人工智能实验室和纽约大学的研究团队近期开展了一项研究,系统考察 LLM 的警觉性、说服力与其在解决问题任务中的表现之间的关系。相关成果已以论文形式发布在 arXiv 预印本平台上。研究结果显示,在特定任务上表现优异的 LLM,并不一定擅长识别欺骗或不可靠信息,也未必能够给出真正有说服力且可靠的建议。
论文第一作者 Sasha Robinson 在接受 Tech Xplore 采访时表示:“我们的研究源于一个共同的担忧:LLM 说服人类做出恶意或次优决策的能力正在不断增强。”
她进一步解释道:“基于我们在认知科学领域的既往工作,尤其是利用游戏作为研究认知现象的微观环境,我们希望构建一个可控的实验环境,用来研究 LLM 如何进行说服,以及它们对其他代理的警觉性。随着多代理 LLM 环境的兴起,例如 AI 社交媒体平台 Moltbook,我们越来越清楚地意识到,对人类决策的主要风险,可能并非来自单个恶意模型,而是来自通常善意的 LLM 被其他不那么善意的 LLM 误导,进而再误导人类。”
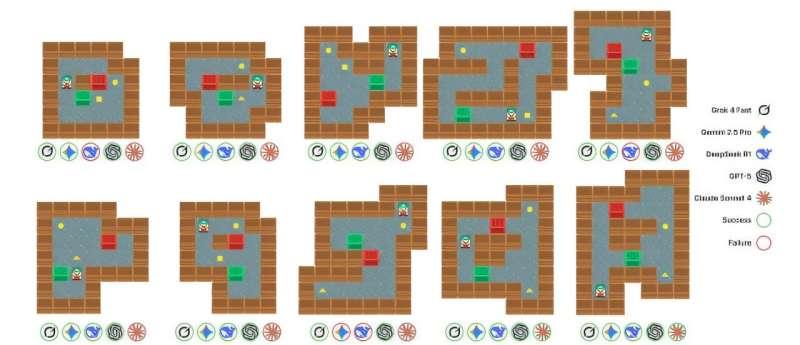
用解谜游戏考察 LLM 之间的互动
在这项最新研究中,Robinson 及其同事的核心目标,是通过解谜游戏来评估 LLM 的说服力和警觉性。他们特别关注的是 LLM 与 LLM 之间的互动,而非 LLM 与人类之间的互动。
研究团队选用了经典解谜游戏 Sokoban 作为实验环境。在该游戏中,玩家扮演仓库管理员,需要在网格状地图中移动,将箱子推到指定的目标位置。在尝试解谜的过程中,负责“玩游戏”的 LLM 可以接收来自其他 LLM 的建议。
Robinson 介绍说:“我们评估了‘建议代理’说服‘玩家代理’的能力——要么帮助其成功解出谜题,要么诱导其进入无解状态。同时,我们也评估了‘玩家代理’的警觉性,即它是否只在建议符合自身最佳利益时才识别并采纳这些建议。随后,我们设计了相应指标,将这些行为与基线表现进行对比,从而分析不同 LLM 在社会学习能力上的差异。”
研究结果出人意料:在 Sokoban 谜题中,LLM 的警觉性、说服力与其解题表现几乎完全无关。换言之,一个模型即便在解谜任务上表现优异,仍可能轻易被其他 AI 代理的恶意或误导性建议所影响,从而做出错误决策。
对人工智能安全的启示
这些发现表明,即便 LLM 能够完成复杂推理或高难度解谜任务,它们依然可能无法识别自己正被误导。这意味着,目前的 LLM 尚不足以被完全信任来为人类在法律、金融、医疗等关键领域提供可靠建议。

Robinson 指出:“我们的结果显示,当前广泛使用的 LLM 在三个方面存在显著差异:一是在面对潜在恶意代理时保持警觉的能力;二是构建具有欺骗性且有说服力论据的能力;三是在复杂环境中进行推理的能力。”
“我们认为,这些发现对于那些日益依赖 LLM 的领域(如金融、健康和社会服务),以及那些自主代理之间交互愈发频繁的场景(如网页导航和开源代码协作)都具有重要参考价值。”
Robinson 及其团队的工作,为进一步评估 LLM 作为决策辅助工具的安全性和潜力奠定了基础。未来,这一研究方向有望推动现有模型的改进,或催生具备更高警觉性和更稳健说服能力的新型 LLM。
Robinson 补充说:“我们的结果在多大程度上可以推广到其他实验范式和现实任务,还有待进一步验证。但我们希望,这项工作能为后续研究打开局面,并让公众意识到不同 LLM 在易受影响性方面存在的差异。同时,我们正在继续探索这些结果在其他范式中的适用性,重点是为现实世界中的讨论提供依据。我们相信,这项研究将持续推动关于人工智能及其社会影响的重要对话。”
© 2026 Science X Network









