

如果向 ChatGPT 询问“上个月新任命的部长是谁?”,却得到一年前部长的名字,这就是人工智能无法正确反映最新现实信息的典型问题。为解决这一局限,韩国科学技术院(KAIST)研究团队开发出一项新评估技术,能够自动跟踪现实世界信息的变化,并识别那些表面正确、实则存在“时间错误”的回答,有望显著提升人工智能系统的可靠性。
新系统:专门测试 AI 的“时间感知”
由 KAIST 电气工程学院 Steven Euijong Whang 教授领衔、联合微软研究院的团队,构建了一套利用时间数据库技术,自动评估和诊断大型语言模型(LLMs)时间推理能力的系统。
相关研究以《利用时间数据库系统性评估大型语言模型中事实性时间敏感问答能力》为题,已发布在 arXiv 预印本平台。
在现实应用中,人工智能要想获得用户信任,必须能够准确理解和反映不断变化的现实世界信息。然而,现有评估方法大多只检查“答案是否一致”,难以刻画复杂的时间关系,无法充分覆盖真实环境中多样化的时间敏感问题场景。
把时间数据库引入 AI 评估
为应对这一难题,研究团队首次将已被验证约 40 年的时间数据库设计理论引入人工智能评估领域。该方法利用数据的时间演化特性及其关系结构,从数据库中自动生成 13 类复杂的时间相关问题,而无需人工逐题设计评测题库。
这一点被视为关键创新:评估题目不再依赖专家手动编写,而是由底层数据自动驱动生成,大幅改变了传统评估流程。
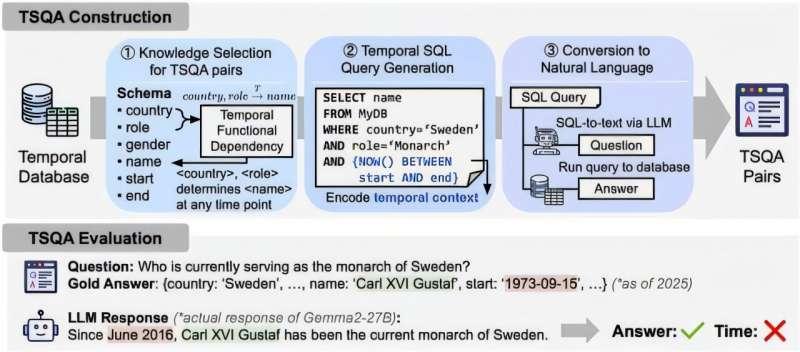
同时,从题目生成、答案推导到结果验证的整个过程都实现了自动化,极大减轻了维护负担,不必像过去那样频繁手动修改或更新题目内容。
自动保持评估与现实同步
当现实世界的信息发生变化时,只需更新数据库中的相关记录,系统就会自动更新对应的评估题目、标准答案以及验证规则。最新信息的录入可由外部数据源或管理员完成,而该技术会在数据更新后自动执行整体评估流程。
此外,研究团队并未局限于“最终答案对不对”的传统评估方式,而是提出了一项新的评估指标,用于检查模型在回答过程中给出的日期或时间区间是否在逻辑上自洽、合理。
借助这一指标,系统在识别“时间幻觉”方面的平均准确率提升了 21.7%。所谓“时间幻觉”,指的是回答内容表面看似正确,但其背后的时间依据或时间线是错误的。
降低维护成本并拓展应用前景
研究显示,采用该技术后,评估系统的维护成本可显著下降:当信息发生变化时,只需更新数据库即可,无需大规模重写题目。与传统方法相比,所需输入数据量平均减少了 51%。
Steven Euijong Whang 教授表示,这项工作展示了经典数据库设计理论在解决当代人工智能可靠性问题上的关键价值。通过将大量专业领域数据转化为可复用的评估资源,团队期待这一技术未来能成为验证医疗、法律等多个关键领域中人工智能性能的实用基础设施。









