

东京大学与Mantra的联合研究团队正式公开面向漫画理解AI的数据集新版「Manga109-v2026」。这一版本在东京大学 相泽・山崎・松井研究室构建的日本漫画数据集「Manga109」基础上,对其中的对话文本标注进行了大规模重审与修订,使其更适合当前的OCR、机器翻译以及多模态理解等任务。
自5月21日起,修订完成的「Manga109-v2026」已在 Hugging Face 上开始分发。相关论文《Manga109-v2026: Revisiting Manga109 Annotations for Modern Manga Understanding》也已被 ICML 2026 的 Culture × AI Workshop 录用。
为现代漫画理解AI更新基础数据集
Manga109 是一个面向学术研究的日本商业漫画数据集,由 109 本漫画、共 2万1142 页构成。数据集中包含分镜(コマ)、角色、面部、身体、文本区域等多种标注,长期被用于漫画OCR、机器翻译、检索以及多模态理解等研究。
随着生成式AI和大规模多模态模型的快速发展,AI在处理漫画时所需的标注精度和结构也在发生变化。漫画是一种将画面、分镜布局、对话气泡、台词、拟声词(オノマトペ)、视线引导等多种元素综合在一起的复杂表达形式,仅仅识别图像中的文字远不足以支撑深入理解。
研究团队因此重新审视了原有 Manga109 中的对话文本标注,对不符合当代OCR和漫画理解任务需求的部分进行了系统梳理与修订。
修订约2.9万条标注,占整体19.6%
在「Manga109-v2026」中,约有 2万9000 条对话文本标注被修正,占 Manga109 全部 14万7887 条文本标注的约 19.6%。
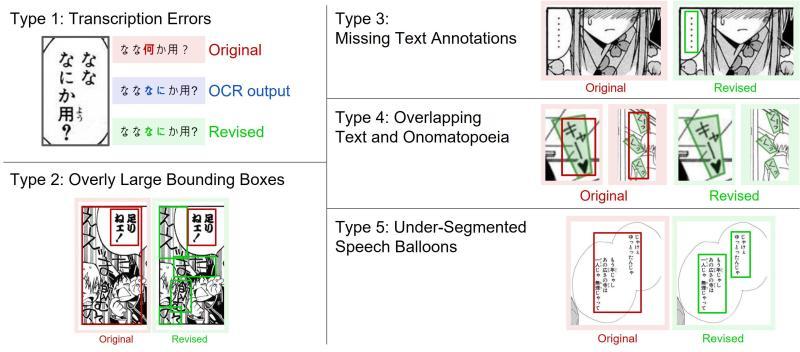
本次重点修订的标注问题被归纳为五大类:
- 文字转写错误(文字起こしの誤り)
- 边界框范围过大(过大なバウンディングボックス)
- 本应标注却被遗漏的文本区域(未アノテーションの文字領域)
- 台词与拟声词区域相互重叠(セリフとオノマトペの重なり)
- 多个对话气泡被错误地合并为一个区域、缺乏细分(吹き出しの分割不足)
Manga109-v2026 中修订的五类标注示例:包括文字转写错误、边界框过大、未标注文本、与拟声词重叠、对话气泡分割不足等问题的整理与修正

在修订过程中,团队利用 Mantra 为漫画翻译开发的商用 OCR API,将其输出结果与既有标注进行比对,以自动检测潜在问题候选。但研究者并未直接将 OCR 输出视为“标准答案”,而是结合人工核查与修正,对数据集进行了精细化整理。
在保留漫画表现结构的前提下优化AI适配性
此次更新的关键点在于:并非简单“清洗”或统一化文本,而是在尽量保留漫画特有表现结构的前提下,提高其与现代AI处理流程之间的一致性。
在漫画中,拟声词以及手写风格的文字,常用于传达场景中的声音、动作、情绪与氛围。如果台词区域与拟声词区域在标注中混在一起,就可能对 OCR、翻译以及场景理解等任务造成干扰。
同样地,当多个对话气泡被标注为一个整体区域时,AI系统就难以正确把握阅读顺序和发话单位。Manga109-v2026 在修订时充分考虑了这些漫画特有的结构特征,对标注进行了更细致的拆分与调整,使其更适合现代 AI 系统进行处理和建模。
OCR 评估 H-mean 从 48.5 提升至 62.9
研究团队还基于修订前后的标注,对 OCR 性能评估的影响进行了对比实验。结果显示,在端到端 OCR 评估中,H-mean 指标由修订前的 48.5 提升至 62.9,提升幅度为 14.4 个百分点。
这一结果表明,如果继续沿用旧版标注,可能会导致对现代 OCR 系统性能的评估出现偏差。更新后的 Manga109-v2026 有望成为漫画 OCR、翻译以及多模态理解研究中更为可靠的评测基准。
兼顾创作者权利的研究基础设施
Manga109 以日本职业漫画家的商业作品为对象,在取得作者许可的前提下构建,仅限研究用途。在此基础上,数据集中 109 本作品中的 87 本还被整理为可商用利用的子集「Manga109-s」,为产业界应用提供了更灵活的选择。
伴随生成式AI与多模态AI的发展,以漫画为对象的 OCR、翻译、检索、内容理解以及创作辅助等研究正不断扩展。Manga109-v2026 的发布,既在标注质量层面提升了数据集对现代任务的适配度,也在版权与权利处理方面提供了清晰边界,为后续相关研究与应用提供了可放心参照的基础设施。









