

前 OpenAI 首席技术官(CTO)米拉·穆拉蒂(Mira Murati)领导的 AI 初创公司 Thinking Machines Lab,于 2026 年 5 月 11 日(当地时间)发布了其实时协同 AI「Interaction Models」的研究预览。这一模型被设计为能够持续接收和处理语音、视频与文本输入,并在此基础上进行实时响应和行动。穆拉蒂曾于 2022 年 5 月出任 OpenAI 的 CTO。
Thinking Machines Lab 认为,现有主流的 AI 模型与交互界面,并未真正针对「人类持续参与的协同工作」进行优化。传统的聊天式 AI 采用的是类似「轮流发言」的回合制结构:用户必须先完成输入,模型才开始生成回复;而在模型生成回复的过程中,又无法接收新的信息。这种交替式的交互方式,使得用户在任务进行中临时改变想法、修正目标或补充意图时,很难顺畅地传达给 AI。
@YouTube
持续处理语音、视频与文本,实现自然打断与同步对话
「Interaction Models」的目标,是把「交互本身」变成模型的内在能力,而不是依赖外部系统来管理对话轮次或处理打断。模型可以连续地处理语音、视频和文本流,使得以下行为成为可能:
- 用户和 AI 可以同时说话,而不是严格轮流发言
- 用户可以在对话中途随时打断或更正
- AI 能够根据屏幕内容或画面变化即时做出反应
在此基础上,团队设想的功能包括:基于对话上下文的对话管理、根据语音和视觉信号进行智能打断、同声发话(overlap speech)、时间感知、调用搜索与外部工具、以及自动生成交互式界面等。比如,用户在说话过程中临时发现自己口误,可以直接更正;或者在编写代码、操作软件时,AI 一边「看」着屏幕,一边在合适的时机主动提醒或协助。
以 200 毫秒为单位的「micro-turn」保证实时性
在技术设计上,「Interaction Models」采用了其称为「time-aligned micro-turn」的机制。与传统回合制模型将输入与输出视为交替出现的两串 token 不同,这一模型把输入和输出都拆分为以 200 毫秒为粒度的连续时间片来处理。
通过这种方式,模型不仅能理解完整的语句,还能把停顿、重叠发言、打断等细微的时间特征纳入语境之中。
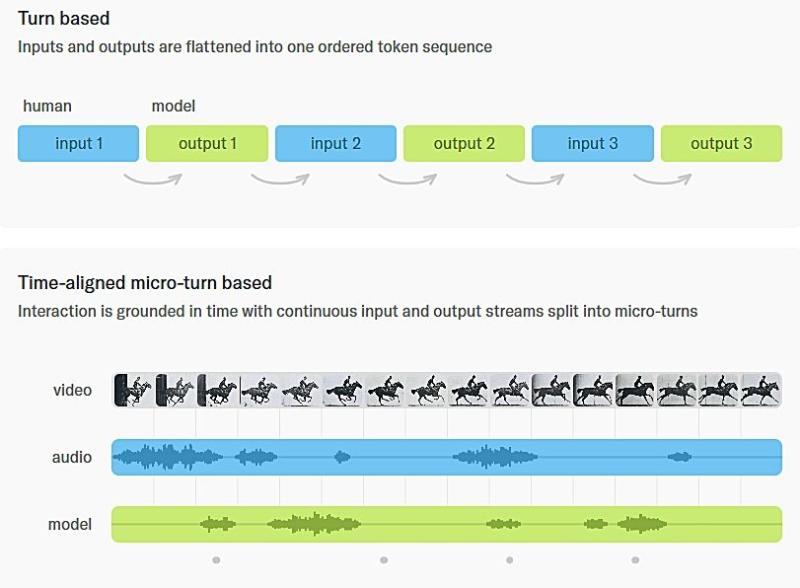

在这一机制下,模型不再只是「等用户说完再回答」,而是可以:
- 一边倾听,一边以语气词或简短回应进行「相应」
- 在用户尚未说完时,基于已获取的信息进行纠正或补充
- 实时观察视频或屏幕内容的变化,并立即做出反馈
复杂推理交给后台模型,前台模型保持实时对话
「Interaction Models」采用前台与后台协同的架构:前台的交互模型负责即时响应与实时对话,后台模型则负责更长时延的复杂推理和工具调用。
在实际使用中,交互模型会持续留在「对话现场」,不断接收用户的新输入并维持对话流畅度;当需要更深入的推理或外部工具支持时,再将任务转交给后台模型处理。后台模型完成推理后,交互模型会在合适的时机把结果自然地融入正在进行的对话中。
Thinking Machines Lab 表示,这种设计可以在「即时反馈」与「深度推理」之间取得平衡:既不牺牲实时性,又能在需要时调用更强大的计算能力。
以 TML-Interaction-Small 验证性能,将开启限量研究预览
在本次研究预览中,团队公布了自家模型「TML-Interaction-Small」的部分评估结果。在 FD-bench v1.5 基准测试中,该模型的平均得分为 77.8;在 FD-bench v1 的回合切换延迟(turn-taking latency)测试中,记录为 0.40 秒。此外,团队还进行了内部基准测试,用于评估模型在时间感知、同声发话以及根据视频变化进行发言等方面的能力。
不过,长时间的语音与视频输入会导致上下文快速累积,对低延迟流式处理提出更高要求,也需要稳定的网络连接来支撑。同时,实时交互场景下的安全性与对齐(alignment)问题,与传统的文本回合制对话相比也更为复杂,需要采用不同的策略。
据介绍,TML-Interaction-Small 是一个 2760 亿参数规模的 MoE(Mixture of Experts,专家混合)模型,其中实际参与推理的「激活参数」约为 120 亿。公司方面表示,目前更大规模的预训练模型在这一用途中仍然偏慢,因此暂不提供;计划在 2026 年下半年推出更大模型,并逐步开放。
Thinking Machines Lab 预计将在未来数个月内启动小范围的研究预览,并在 2026 年下半年面向更广泛的用户群体开放使用。









