

人工智能系统,如大型语言模型(LLMs)和卷积神经网络(CNNs),能够处理海量数据,快速生成内容或识别复杂模式。但当这些模型运行在现有硬件(如智能手机、笔记本电脑和平板电脑)上时,往往需要消耗大量电能。
过去十多年里,电子工程领域持续探索更高效的AI专用硬件。其中一条重要路径是“类脑计算”——从人脑的结构和工作方式中汲取灵感,设计出在能效上更接近大脑的计算系统。
华中科技大学与香港中文大学的研究人员近期提出了一种基于二维材料的类脑计算新方案。他们在《自然电子学》(Nature Electronics)上发表论文,介绍了一款基于二维半导体二硫化钼(MoS2)的芯片,该芯片能够稳定运行人工智能算法,同时显著降低功耗。
研究团队指出,基于MoS2等二维材料的器件,具有较高的电静态可控性,非常适合用来构建“计算与存储一体化”的类脑硬件。然而,要将这类硬件扩展到更大规模,以满足边缘人工智能平台的应用需求,仍面临关键挑战。
其中一个核心难题是“权重精度与能效之间的权衡”:
- 提高权重精度通常需要更高的工作电压,以编码更多导电状态;
- 或者采用复杂的校准、补偿方案来减小器件间差异。
这些做法虽然能提升计算精度,但会显著增加能耗,削弱类脑硬件在能效上的优势。
新型类脑硬件与信号折叠方案
为解决上述问题,Tong、Xu及其合作者设计了一种紧凑的类脑电子系统,用于支持AI计算。该系统采用基于MoS2的垂直“一晶体管一电阻”(1T1R)交叉阵列结构,即晶体管与电阻交替连接形成的网格,用于执行核心计算任务。
在此基础上,研究人员提出了一种新的“信号折叠”策略,目标是在不牺牲模型精度的前提下,进一步降低功耗。其基本思路是:
- 在进行计算时降低工作电压;
- 同时减小底层器件之间的差异对整体精度的影响。
具体而言,该方法包含两种折叠方式:
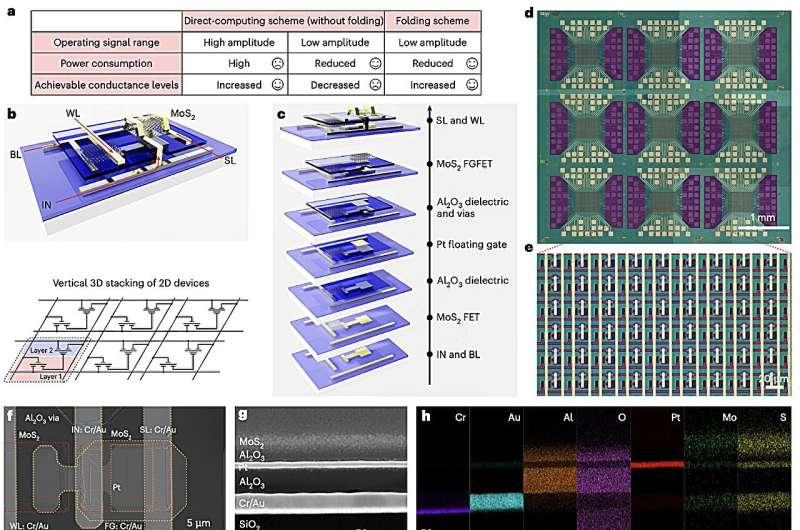
- 输入信号折叠:通过对输入信号进行折叠编码,降低运算所需的工作电压;
- 权重导电折叠:通过对权重的导电状态进行折叠编码,弱化器件间不一致性带来的误差,从而扩展可实现的权重精度。
在这两种方案中,输入与权重信号都被重新编码为由两种折叠信号组合而成的形式,并由垂直1T1R MoS2交叉阵列来实现向量-矩阵乘法等核心运算。
显著降低AI计算功耗
研究团队利用这款类脑芯片进行了多轮实验,重点测试其在向量-矩阵乘法任务上的表现——这类运算是多种人工神经网络(包括LLMs和CNNs)推理过程的基础。
他们将采用信号折叠方案的芯片,与未使用信号折叠的传统实现进行了对比。结果显示:
- 在保持相近计算准确度的前提下,
- 采用信号折叠的方案可将向量-矩阵乘法的功耗最高降低约90%,
- 且无需依赖额外的校准或补偿电路来修正硬件不一致性。
换言之,该类脑芯片能够准确表示神经网络中的数值权重和计算结果,同时避免了传统高能耗校正方案带来的额外开销。
作者在论文中总结称,相比未折叠信号的计算方式,这一信号折叠设计在能效上具有显著优势,而计算精度基本保持不变。
面向低功耗边缘AI的潜在应用
这项工作展示了一条有前景的路径:通过在电路与信号编码层面引入“折叠”设计,可以在不增加系统复杂度的情况下,大幅降低类脑计算硬件的能耗。
未来,类似的信号折叠策略有望被进一步拓展和优化,用于更多类型的类脑芯片设计。研究团队开发的这款基于MoS2的芯片,也有潜力继续改进,并集成到各类本地运行AI算法的终端设备中,例如智能手机、可穿戴设备、物联网节点等,为边缘人工智能提供更高能效的硬件基础。
© 2026 Science X Network









